最近几年总觉得脑子不够用,一会想学这个,一会想看哪个,一天可能一行代码也没写就这么度过了。
这个文章就当自己的学习记录吧,想到什么写什么,虽然有有道笔记,但是里面的记录的东西太乱了,
感觉就是个查问题的笔记库,有时间再整理下吧。。。
20170222
1.关于数据库的分库分表,主从技术落地。
20170223
1.以后面试要首先问涨薪体系!
2.批处理数据的时候,要控制数据的数量,比如批量插入的时候,每次循环1000条插入一次,不要一次性插入N条,防止堆内存溢出。
20170224
1.日志输出规范
20170227
1.el字符串按照指定规则截取
<c:set value="${ fn:split(cate.services , ' ') }" var="service" />
<c:forEach items="${service}" var="s">
<c:if test="${s==7}">
<c:set var="freePost" value="true" />
</c:if>
</c:forEach>
2.mysql查询分页limit写法优化
写法一:
select * from tb_order LIMIT 999999 ,10
写法二:
select * from tb_order where id>=(
select id from tb_order LIMIT 999999,1) LIMIT 10
mysql limit会扫描n行,如果这个n偏移量过大会导致性能下降,
在id递增的情况下建议使用下面的写法
20170228
1.防止xss需要对输入内容进行转译保存,页面显示是转译后的标签。
StringEscapeUtils.escapeHtml4()
spring 可以这样写
@InitBinder
protected void initBinder2(WebDataBinder binder) {
// String类型转换,将所有传递进来的String进行HTML编码,防止XSS攻击
binder.registerCustomEditor(String.class, new PropertyEditorSupport() {
public String getAsText() {
Object value = getValue();
return value != null ? value.toString() : "";
}
public void setAsText(String text) {
setValue(text == null ? null : StringEscapeUtils.escapeHtml4(text.trim()));
}
});
}
2.高并发下面redis的小问题
redis因为是单线程的,如果在高并发的情况下 reidis服务器没有设置集群或者主从,连接数都是有限的,
在大量请求过来后,如果redis连接不够用会导致请求响应非常慢。我们可以在团购开始时间之前,将热数据
先从库同步到redis,同时定时也在项目里面缓存一份,拿数据的时候优先从本地缓存里面拿,定时再从redis
里面同步数据到本地缓存。
整个数据链路是 DB==>REDIS==>本地缓存
20170301
1.tomcat的日志问题
昨天线上突然挂机,想去看下tomcat挂机时候的日志,没想到catalina.log里面打了一堆乱七八糟的日志,
catalina.log会记录一些RunTimeException 和 System.out.println() 和 e.printStackTrace(),为了防止
catalina.out日志过大,不要在代码里面这样输出内容。
20170302
1.java垃圾回收知识点回顾
java垃圾回收采用复制算法,将内存分为一块较大的eden空间和两块较小的survivor空间。每次都是使用eden和其中的一块survivor空间。
当回收时,将eden和survivor中还存活着的对象一次性的拷贝到另外一块survivor空间上,最后清理掉刚刚用掉的eden和survivor的空间
新生代=eden+surviror1+surviror2垃圾回收时候首先
先将eden+surviror1 移到surviror2 如果surviror2内存不够 就移到老年代 如果老年代还不够放,那就进行fulg
JVM的方法区,也被称为永久代。在这里都是放着一些被虚拟机加载的类信息,静态变量,常量等数据。这个区中的东西比老年代和新生代更不容易回收
当年轻代内存满时,会引发一次普通GC,该GC仅回收年轻代。需要强调的时,年轻代满是指Eden代满,Survivor满不会引发GC
当年老代满时会引发Full GC,Full GC将会同时回收年轻代、年老代
当永久代满时也会引发Full GC,会导致Class、Method元信息的卸载
q&a surviror什么时候才会存放对象
当eden第一次发生ygc的时候,会将eden区域的存活的对象拷贝到survivor from,survivor 放不下的会放到老年代
当eden第二次ygc,会将eden区域的存活的对象和survivor from存活的对象拷贝到 survivor to,放不下的会放到老年代,然后清空survivor from
这个时候,“From”和“To”会交换他们的角色,也就是新的“To”就是上次GC前的“From”,新的“From”就是上次GC前的“To”。
不管怎样,都会保证名为To的Survivor区域是空的。Minor GC会一直重复这样的过程,直到“To”区被填满,“To”区被填满之后,会将所有对象移动到年老代中
2.系统流量控制
参考博客
分流:不需要我们控制,h5
降级:
当业务系统挂了的时候,可以进行降级,降级方式有手动降级和自动降级
缓存:
本地缓存==》redis缓存==》DB
限流:
限流总并发/连接/请求数:Apache和tomcat做
限流某个接口的总并发/请求数:apiAuthJAR可以做
限流某个接口的时间窗请求数:apiAuthJAR可以做
平滑限流某个接口的请求数:令牌桶算法可以应对突发请求 apiAuthJAR可以做
接入层:nginx限流
20170306
java 性能监控常用命令
- jstack 查看线程
jstack pid 需要注意dump文件里面的 deadlock和blocked
jstack pid >a.txt
grep -n -E10 ‘deadlock’ a.txt - jmap(查看内存)
jmap -dump:format=b,file=/tmp/dump.dat 4813
可以dump出java当前内存的情况,然后用工具MemoryAnalyzer或者HeapAnalyzer进行分析
jmap -heap
jmap -histo: 打印当前java堆中各个对象的数量、大小
jmap -histo:live 20881 | grep QueryPartnerImpl jstat(性能分析)
jstat -gcutil 1756 1000
S0(from区)使用了41.74%;
S1(to区)使用了0;
E(Eden区)使用了54.35%;
O(Old,年老代)使用了62.41%;
P(Perment,永久代)使用了99.63%;
YGC(Young GC)了32次,
YGCT(Young GC Time)花销0.132秒;
FGC(Full GC)了1次,
FGCT(Full GC Time)花销0.102秒;
GCT(GC Time)总花销0.234秒。jstat -gc 1688 3000
S0C:年轻代中第一个survivor(幸存区)的容量 (字节)
S1C:年轻代中第二个survivor(幸存区)的容量 (字节)
S0U:年轻代中第一个survivor(幸存区)目前已使用空间 (字节)
S1U:年轻代中第二个survivor(幸存区)目前已使用空间 (字节)
EC:年轻代中Eden(伊甸园)的容量 (字节)
EU:年轻代中Eden(伊甸园)目前已使用空间 (字节)
OC:Old代的容量 (字节)
OU:Old代目前已使用空间 (字节)
PC:Perm(持久代)的容量 (字节)
PU:Perm(持久代)目前已使用空间 (字节)
MC: 元空间(Metaspace) Metaspace capacity (kB),一般是方法区,不在虚拟机中,而是使用本地内存,
jdk8移除了PermGen,取而代之的是MetaSpace
CCSC: Compressed class space capacity (kB).
- jstack 查看线程
例子: nohup java -Dmail.mime.splitlongparameters=false -Xms4096m -Xmx4096m -Xss256k -XX:NewRatio=3
-XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=80 -XX:+UseCMSInitiatingOccupancyOnly -XX:+DisableExplicitGC
-XX:+ExplicitGCInvokesConcurrent -XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/data/log/ -XX:+PrintGCDetails -jar pig-upms/pig-upms-biz/target/pig-upms-biz.jar >/dev/null 2>&1&
jstat -gc 例子:
S0C S1C S0U S1U EC EU OC OU
104832.0 104832.0 0.0 1882.5 838912.0 489094.9 3145728.0 676408.2
MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
133500.0 124153.3 16072.0 14414.1 1833 48.811 8 0.683 49.494
-Xms4096m -Xmx4096m java堆的最大和最小4G
-XX:NewRatio=3
新生代与老年代的比例是1:3 新生代为1/4 老年代 3/4,
所以上面的 老年代大小OC=3145728/1024=3072M 和 4096m * 3/4 一样
-XX:SurvivorRatio=8
没有配置新生代的SurvivorRatio,默认是8
su0 :su1: eden比例为1:1:8
su0大小=104832/1024=102M 和 4096m *1/4 * 1/10=102M 一样
4. 查询最占用cpu的方法
ps -mp 28155 -o THREAD,tid,time
查询出最耗时的tid 28159
然后 jstack 28155 > test.txt 将当期pid的栈信息打印到text.txt里面
然后 grep `printf "%x\n" 28159` test -A 30
jvm 性能优化
- 堆和栈常用参数
java堆: -Xms2560m -Xmx2560m 限制java堆大小为 2560MB,且不可扩展,如果程序Headp java栈: -Xss256k 设置java线程栈的大小,如果程序 StackOverflow就需要将xss设置大一点 java年轻代: -XX:NewSize=1024m # 年轻代默认初始大小 jdk(1.3/1.4有用) -XX:MaxNewSize=1024m # 年轻代最大值 (1.3/1.4有用) 以上两个等于-Xmn1024M(jdk1.4有用) 年轻代大小 java永久代 -XX:PermSize=384m # 永久代默认初始大小(方法区,类、接口、方法等) -XX:MaxPermSize=512m # 永久代最大值 SurvivorRatio=8 则就是2:8 一个Survivor则为1/10 新生代=一个eden+两个survivor区 如果是SurvivorRatio=4 则就是2:4 一个Survivor则为1/6 -XX:SurvivorRatio=8 设置年轻中Eden区与Survivor区的大小比值 -XX:NewRatio=3 表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4 设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代) 垃圾回收信息和内存溢出dump
stop-the-world耗时过长可能是由于GC参数不合理或者代码实现不正确 使用-XX:+PrintFlagsFinal and -XX:+PrintFlagsInitial 可以打印jvm启动时候加载的配置项 gc时候打印详情 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCApplicationConcurrentTime -XX:+PrintHeapAtGC -Xloggc:/data/applogs/heap_trace.txt 内存溢出dump -XX:-HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data/applogs/HeapDumpOnOutOfMemoryError垃圾收集器
使用 ParNew 收集器 (只有 Serial 和 ParNew 这两个年轻代收集器可以和老年代的 CMS 收集器一起使用,ParNew 是多线程的) -XX:+UseParNewGC:设置并行收集器 使用 ParNew + CMS + Serial Old,Serial Old 会在 CMS 预留内存超过 CMSInitiatingOccupancyFraction 设置的比例时触发使用 -XX:+UseConcMarkSweepGC 设置并发收集器 CMS 无法做彻底清除,需预留一部分空间供并发收集时程序使用,这个设置预留比例40% -XX:CMSInitiatingOccupancyFraction=60 如果没有这个参数, 只有第一次会使用 CMSInitiatingPermOccupancyFraction=70 这个值,后面的情况会自动调整 -XX:+UseCMSInitiatingOccupancyOnly 设置永久代使用超过 70% 触发 CMS GC -XX:CMSInitiatingPermOccupancyFraction=70并发收集器设置
并行 GC 时进行内存回收的线程数 -XX:ParallelGCThreads=4 设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代 对象每坚持一次 Minor GC 后年龄+1,当超过这个数值后进入老年代 晋升年龄最大阈值,默认15。在新生代中对象存活次数(经过YGC的次数)后仍然存活,就会晋升到老年代。每经过一次YGC,年龄加1, 当survivor区的对象年龄达到TenuringThreshold时,表示该对象是长存活对象,就会直接晋升到老年代。 -XX:MaxTenuringThreshold=9 # 为了减少 CMS 重新标记的暂停时间,开启并行remark -XX:+CMSParallelRemarkEnabled # 当使用 CMS 时希望又保留部分 System.gc() 的功能,只不过这种情况下触发的不是系统GC,而是 CMS GC -XX:+ExplicitGCInvokesConcurrent # 早期版本也需要设置这个才会回收永久代 -XX:+CMSPermGenSweepingEnabled # 只有设置才会让永久代触发 CMS GC -XX:+CMSClassUnloadingEnabled
- 堆和栈常用参数
调优总结
[参考文章]("http://www.importnew.com/13954.html")年轻代大小选择
响应时间优先的应用:尽可能设大,直到接近系统的最低响应时间限制 吞吐量优先的应用:尽可能的设置大年老代大小选择
吞吐量优先的应用:一般吞吐量优先的应用都有一个很大的年轻代和一个较小的年老代
20170308
linux常用命令值删除多个进程
grep -v 是用来排除某一行数据的 ps -ef|grep 'java' |grep -v grep|cut -c 9-15|xargs kill -9elasticsearch 安装插件
安装集群管理软件 elasticsearch/bin/plugin install mobz/elasticsearch-head 安装zk分词 git checkout tags/{version} mvn package copy and unzip target/releases/elasticsearch-analysis-ik-{version}.zip to your-es-root/plugins/ik3.ela启动不能用root
因为安全问题elasticsearch 不让用root用户直接运行,所以要创建新用户 userAdd ela 启动时候 切换到su ela用户 ./elasticserach -d 需要修改配置文件的端口号和elasticserarch.sh里面启动的Xms和Xmx的堆大小- wc -l -n
20170309-redis回顾
redis支持多种数据格式,还支持Geo坐标经纬度,HyperLogLog(基数统计)、Pub/Sub。
redis的key和string类型value限制均为512MB。
redis两种持久化方式
一、Snapshot
以快照的形式保存某一时刻的数据在磁盘,
save <seconds> <changes>
#在bgsave遇到error的时候是否停止持久化,默认是yes代表是,no代表不是
stop-writes-on-bgsave-error yes
#是否压缩,默认是yes代表是,no代表不是,如果想节省CPU的话就设为no,但是rdb文件会比较大
rdbcompression yes
#持久化的文件名字,默认是dump.rdb
dbfilename dump.rdb
#文件存放目录默认是redis.conf所在的目录./
dir ./
save <seconds> <changes>:在X秒内如果key有至少X次改变就触发持久化,
例如save 900 1的话就是在900秒如果key有至少1次改变就触发持久化。
如果想关闭此功能的话,可以把全部save行都注释或删除或者使用save
二、append-only file(aof)
以追加的方式记录所有写操作的命令到磁盘文件里面,
#appendonly:是否启动aof,默认是no代表不启用,yes代表启用
appendonly no
#aof的文件名,默认是appendonly.aof
appendfilename "appendonly.aof"
#触发的间隔,默认是everysec代表每秒,另外还有always代表有改变都触发,性能最差但数据最安全,
#no代表让OS自己决定什么时候执行,性能最好但数据不安全
appendfsync everysec
dir ./
Redis会定期做aof重写,压缩aof文件日志大小
三、Snapshot和AOF的对比
snapshot 如果在保存前服务器down了,那么在上次snapshot之后修改的数据会丢失。
而AOF是记录所有的写操作,在数据完整性来说,AOF比snapshot要好
aof一般是比rdb文件较大(所有写命令),恢复时间较长,因为要重新执行所有的写操作
所以如果你可以容忍数据丢失的话,可以使用snapshot方式,
而且也是比AOF要节省资源,否则的话就使用AOF方式,
或者同时使用2种方式(重启的时候会优先使用AOF)。
redis 关闭命令
以前都是kill 太暴力了 src/redis-cli -a gaoguangjin shutdown- redis 批量处理
如批量根据key查询结果或者批量插入 用pipeline管道操作。
- redis hgetAll 有性能问题,不能一次性存储大量数据。
- redis pipeline原理
一开始觉得redis transation 与redis的pipeline类似,都是把所有命令打包后,
再一起发给服务端,其实这种理解是错误的。
一般情况下redis是
request->response
request->response
request->response
这种阻塞是请求流程,当如果有批量的操作的时候
这种请求模式会有性能瓶颈的。
pipeline模式不用等待请求结果,一直发送命令,最后一次性获取。
transtaion模式是一次性发,一次性取,保证操作一致性。
如果有非常多的命令,也并不是一次性全部发送完最好,毕竟服务器是需要维护一个队列存储结果的,
如果命令太多,最好是分批,redis对此的建议是一万个
- redis transtaion
redis的事物被提交,事物中的所有操作会顺序执行,且事物执行期间,其他client的操作会被阻塞,
这样可以保证所有命令可以被执行
但redis的事物也是个伪事物,如果执行过程中某个命令有错误,只是不执行这个命令,
其他命令还是会按顺序执行。
- HyperLogLog
Redis 的基数统计,这个结构可以非常省内存的去统计各种计数,
比如注册 IP 数、每日访问 IP 数、页面实时UV)、在线用户数等。但是它也有局限性,
就是只能统计数量,而没办法去知道具体的内容是什么。
当然用集合也可以解决这个问题。但是一个大型的网站,每天 IP 比如有 100 万,粗算一个 IP 消耗 15 字节,
那么 100 万个 IP 就是 15M。而 HyperLogLog 在 Redis 中每个键占用的内容都是 12K,
理论存储近似接近 2^64 个值,不管存储的内容是什么,它一个基于基数估算的算法,只能比较准确的估算出基数,
可以使用少量固定的内存去存储并识别集合中的唯一元素。而且这个估算的基数并不一定准确,
是一个带有 0.81% 标准错误的近似值。
这个数据结构的命令有三个:PFADD、PFCOUNT、PFMERGE
PFADD RDBMS "MySQL" "MSSQL" "PostgreSQL" 存放3个数据
PFADD nosql "Redis" "MongoDB" "Memcached" 存放3个数据
PFCOUNT nosql 统计值为3
PFMERGE databases RDBMS nosql 可以将两个集合数据合并
- 使用scan代替keys
当 KEYS 命令被用于处理一个大的数据库时, 又或者 SMEMBERS 命令被用于处理一个大的集合键时,
它们可能会阻塞服务器达数秒之久。
假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如果将它们全部找出来,
用keys会导致线程阻塞一段时间
可以使用 scan 0 match key* count 1
redis如何实现延时队列
使用sortedset,拿时间戳作为score,消息内容作为key调用zadd来生产消息,
消费者用zrangebyscore指令获取N秒之前的数据轮询进行处理。- 使用redis zset 数据结构
2.使用score排序 score为过期时间点
3.启动线程不断取出排序第一个 比较score和当前时间点
如果score小于或等于当前时间 说明此数据过期 需要处理 4.处理完毕在zset中移除
- 使用redis zset 数据结构
Redis 的 ZSET 做排行榜时,如果要实现分数相同时按时间顺序排序怎么实现?
将 score 拆成高32位和低32位,高32位存分数,低32位存时间的方法private static final Long COUNT_BITS = 32L;
Long time=System.currentTimeMillis()/1000L;
Thread.sleep(1000);
Long time2=System.currentTimeMillis()/1000L;
Long a=1L;
Long b=2L;
System.out.println(ctlOf(a<<COUNT_BITS,time));
System.out.println(ctlOf(b<<COUNT_BITS,time2));
System.out.println(ctlOf(a<<COUNT_BITS,time2));
System.out.println(ctlOf(b<<COUNT_BITS,time));
private static Long ctlOf(Long id, Long time) {return id | time;}
20170310
nginx安装ssl模块
nginx -V 可以查看原来编译时都带了哪些参数 原来的参数: --prefix=/app/nginx 添加的参数: --with-http_stub_status_module --with-http_ssl_module --with-http_realip_module 步骤如下: 1. 使用参数重新配置: ./configure --prefix=/app/nginx -user=nobody -group=nobody --with-http_stub_status_module \ --with-http_ssl_module --with-http_realip_module \ --add-module=../nginx_upstream_hash-0.3.1/ \ --add-module=../gnosek-nginx-upstream-fair-2131c73/ 2. 编译: make #不要make install,否则就是覆盖安装 3. 替换nginx二进制文件:./objs/是新编译后文件的目录 cp /app/nginx/sbin/nginx /app/nginx/sbin/nginx.bak cp ./objs/nginx /app/nginx/sbin/nginx开启websocket与https
#websocket
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection “Upgrade”;
#https
listen 443 ssl ;
#注意证书目录
ssl_certificate cert/214040861080304.pem;
ssl_certificate_key cert/214040861080304.key;
ssl_session_timeout 5m;
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_prefer_server_ciphers on;
20170313
instanceof 与 isInstance()
instanceof 是一个操作符(类似new, ==等) if (ins instanceof String) { //logic }
isInstance是Class类的一个方法:
特别地,当该 Class 对象表示一个已声明的类时,若指定的 Object 参数是所表示类(或其任一子类)的一个实例,
如果此 Class 对象表示一个数组类,且通过身份转换或扩展引用转换,指定的 Object 参数能转换为一个数组类的对象
如果此 Class 对象表示一个接口,且指定 Object 参数的类或任一超类实现了此接口
if (String.class.isInstance(ins)){
}
//比较类型
对obj.instanceof(class),在编译时编译器需要知道类的具体类型
//反射检查类实现某个接口
对class.isInstance(obj),编译器在运行时才进行类型检查,故可用于反射,泛型中
20170314-浅拷贝和深拷贝
浅拷贝是指拷贝对象时仅拷贝对象本身(包括对象中的基本变量),而不拷贝对象包含的引用指向的对象。
深拷贝不仅拷贝对象本身,而且拷贝对象包含的引用指向的所有对象。
举例来说更加清楚:
对象A1中包含对B1的引用,B1中包含对C1的引用。
浅拷贝A1得到A2,A2 中依然包含对B1的引用,B1中依然包含对C1的引用。
深拷贝则是对浅拷贝的递归,深拷贝A1得到A2,A2中包含对B2(B1的copy)的引用,B2 中包含对C2(C1的copy)的引用。
所谓浅复制:则是只复制对象的引用,两个引用仍然指向同一个对象,在内存中占用同一块内存。
被复制对象的所有变量都含有与原来的对象相同的值,而所有的对其他对象的引用仍然指向原来的对象。
换言之,浅复制仅仅复制所考虑的对象,而不复制它所引用的对象。
深复制:被复制对象的所有变量都含有与原来的对象相同的值,除去那些引用其他对象的变量。
那些引用其他对象的变量将指向被复制过的新对象,而不再是原有的那些被引用的对象。
换言之,深复制把要复制的对象所引用的对象都复制了一遍。
java中如果要实现深拷贝,必须要重写clone()方法来拷贝对象里面的应用类型变量
20170317-java spi机制
SPI为某个接口寻找服务实现的机制,例如日志模块的方案,xml解析模块、jdbc模块。
当服务的提供者,提供了服务接口的一种实现之后,在jar包的META-INF/services/目录里同时创建一个以服务接口命名的文件。
该文件里就是实现该服务接口的具体实现类。
而当外部程序装配这个模块的时候,就能通过该jar包META-INF/services/里的配置文件找到具体的实现类名,并装载实例化,完成模块的注入。
基于这样一个约定就能很好的找到服务接口的实现类,而不需要再代码里制定。jdk提供服务实现查找的一个工具类:java.util.ServiceLoader
在项目class目录下面 META-INF/services/ 会有待实现的接口,文件名称就是接口名称例如:java.sql.Driver
文件里面存放的内容就是接口的实现类名称。
ServiceLoader.load(XX.class) 就可以得到该类的实现类了

20170323
苹果javaPan推送时候报错:Received fatal alert: certificate_revoked
证书过期了,没有及时更新接收推送的设备的客户端的证书和token
20170327
java日志框架兼容
commons-logging和slf4j 都是定义日志框架的接口 log4j和logback 都是实现上面接口的类 java-util-logging:俗称jul commons-logging:简称 jcl **-over-slf4j都是为了适配用的,比如log4j-over-slf4j是将原来log4j打印的转换成logback打印 使用以下架包可以兼容使用logback时候的各种冲突 <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>${slf4j.version}</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>jcl-over-slf4j</artifactId> <version>${slf4j.version}</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>jul-to-slf4j</artifactId> <version>${slf4j.version}</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>log4j-over-slf4j</artifactId> <version>${slf4j.version}</version> </dependency>
20170330
代码性能监控类StopWatch
spring提供的StopWatch可以很容易实现对多个方法调用时间的监控,比较简单明了。当然如果代码里面有多线程代码肯定是不适用的。
20170412
集合类初始容量和负载因子设置
容器类:初始长度/扩容倍数 默认的。如果设置不到导致频繁的resize扩容 - ArrayList:10/1.5 没有扩容因子 - ArrayDeque:8/2 - BitSet:64/2 - HashMap:16/2 扩容因子0.75 - HashSet/TreeSet:同HashMap(基于HashMap实现,value为空Object) 扩容因子0.75 - Hashtable:11/2 扩容因子0.75 - WeakHashMap:同HashMap 扩容因子0.75 - PriorityQueue:11/Double size if small; else grow by 50% - StringBuilder:16/按需20170418
ThreadLocal内存溢出
使用ThreadLocal的时候 记得手动调用remove方法
20170425
- 关于代码解耦
1、可以使用spring的事件驱动模型,订阅者和消费者。
ApplicationContextAware是用来实现发布消息的,ApplicationListener是用来订阅消息的
2、使用google的eventbus 轻量级别的代码层次解耦。
20170510-hs_err_pid.log
JVM致命错误日志(hs_err_pid.log)解读
一般错误原因在第一行就可以看到 # There is insufficient memory for the Java Runtime Environment to continue. # Native memory allocation (mmap) failed to map 6987776 bytes for committing reserved memory. # Possible reasons: # The system is out of physical RAM or swap space # In 32 bit mode, the process size limit was hit # Possible solutions: # Reduce memory load on the system # Increase physical memory or swap space # Check if swap backing store is full # Use 64 bit Java on a 64 bit OS # Decrease Java heap size (-Xmx/-Xms) # Decrease number of Java threads # Decrease Java thread stack sizes (-Xss) # Set larger code cache with -XX:ReservedCodeCacheSize= # This output file may be truncated or incomplete. # # Out of Memory Error (os_linux.cpp:2627), pid=15974, tid=139667856946944
20170512-高可用消息推送平台
1.公司现有的推送系统和参考文章
20170605-mybatis动态参数
1.对于日期类型判断只能判断是否为空,不能这样判断
<if test="createTime != null">
date(create_time) = date(#{createTime,jdbcType=TIMESTAMP})
</if>
如果类型为Integer类型,就去掉 != ”的判断,只判断!=null即可。
如果是字符串类型比较
<if test=" name=='你好' ">
<if>
这样会有问题,换成
<if test=' name=="你好" '>
<if>
2.mybatis特殊字符处理
<![CDATA[ ]]>
3.mybatis 批量插入和插入后获取主键的id值
useGeneratedKeys="true" keyProperty="id"
<insert id="saveBatchArticle" parameterType="java.util.List" useGeneratedKeys="true" keyProperty="id">
insert into tb_article (custom_id,
media_name,title, custom_name,
custom_price, verify_url,
status, flag, create_date,
verify_date)
<foreach collection="list" item="article" separator=" union all ">
select
#{article.customId},#{article.mediaName},#{article.title},#{article.customName},
#{article.customPrice},#{article.verifyUrl},#{article.status},#{article.flag},
#{article.createDate},#{article.verifyDate} from dual
</foreach>
</insert>
4.mybatis in(1,2)条件特殊处理
<select id="findByIdsMap" resultMap="BaseResultMap">
Select
<include refid="Base_Column_List" />
from jria where ID in
<foreach item="item" index="index" collection="list" open="(" separator="," close=")">
#{item}
</foreach>
</select>
20170614-表添加索引
1.好久没有写sql,提个数据库修改单还得按照dba的要求来。
添加索引有以下两种方式
ALTER TABLE API_USERTOKEN add index idx_API_USERTOKEN_TOKEN (TOKEN);
create index IDX_API_USERTOKEN_TOKEN on API_USERTOKEN(TOKEN);
2.删除指定日期数据
delete from MQTT_PUSH_INFO where create_time<(select DATE_FORMAT(date_add(now(), interval -3 MONTH),'%Y-%m-%d 00:00:00'))
3.删除大量数据,truncate不记录日志速度快
truncate table MB_LOG_WAP_VISIT;
20170615-equal和hashcode
如果两个对象equal相等则hashCode一定相等,因为对象的equal比较的是引用地址,
而object的hashcode是native方法返回的也是object的引用地址
String类型重写了native的hashCode方法,只要长度一致,hashCode都是一样的。
如果判断两个对象是否相等最好重写equal和hashCode方法,
例如set和map里面的key值,map里面put值时候首先需要计算其对象的hashCode,
比如两个对象 new student("gaogao","11"),new student("gaogao","11")
如果不重写hashcode 会默认是两个对象存进去。
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}
20170615-replace空指针
如果有多个replace例如
"test".replace("param1",params.getParam1()).replace("param2",params.getParam2()).
replace("param3",params.getParam3()).replace("param4",params.getParam4()).
replace("param5",params.getParam5())
params.getParam1()..params.getParam5()的值不可以为null
20170619-为什么HashMap里面的数组size必须是2的次幂?
//http://nanguocoffee.iteye.com/blog/907824
//hashMap里面有这段源码,将number改成2的次幂
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
//然后将number-1 得到2进制1的个数越多,hash分布的就越均匀
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
//最终都是为了让hash分布的更加均匀点
20170620-http协议复习
20170621-深入java虚拟机复习
java虚拟机运行时数据区域
1、程序计数器:
【1】作用可以定义成查看当前线程所执行的字节码的行号指示器,字节码解释器工作时就是通过改变这个计时器的值来选取下一条需要执行的字节码指令。例如分支,循环异常。线程恢复等功能,
【2】因为多线程是通过线程轮流切换来实现的。在任何一个指定的时刻,一个处理器指挥处理一条线程中的指令,所以每个线程都需要一个独立的程序计数器,是 线程私有
【3】如果线程执行的是ntive方法 则计数器为空。此区域是唯一一个在虚拟机规范中没有任何OutMeoryError
2、java虚拟机栈(Xss) stack
【1】线程私有,描述的是Java方法的内存模型。每个方法被执行都会创建一个栈帧用来存放局部变量表,操作栈、动态链接等。
【2】局部变量表存放了各种基本数据类型 boolean byte char short int float long double 、对象的引用 reference类型(可能是对象起始地址的引用指针)
【3】64位的长度long和double的数据会占用两个局部变量空间(Sloat)【会导致线程安全问题】,其余的都只占用一个。
【4】局部变量表所需要的内存空间都是在编译器完成分配的,在方法运行期间不会改变局部变量表的大小。全局变量是在堆里面,
【5】 线程请求栈深度大于虚拟机允许的深度会抛出StackOverFlowError。如果虚拟机可以动态扩展,当扩展无法申请到足够的内存会抛出OutOfMemoryError异常
3、本地方法栈
【1】 与虚拟机栈发挥作用相似,区别在于本地方法栈执行的是虚拟机使用到的Native方法。而虚拟机栈使用的是java方法服务 。
【2】 线程请求栈深度大于虚拟机允许的深度会抛出StackOverFlowError。如果虚拟机可以动态扩展,当扩展无法申请到足够的内存会抛出OutOfMemoryError异常
4、java堆(-Xmx 和-Xms)heap
【1】Java Heap 是java虚拟机中管理内存最大的一块,所有线程共享的一块内存区域。虚拟机启动时候创建,目的就是存放对象实例,几乎所有对象都在这里分配内存。
【2】Java 虚拟机规范中描述:所有的对象实例以及数组都要在堆上面分配内存。
【3】Java 堆是垃圾收集器管理的主要区域。java堆可分为:新生代和老年代。 再细致点有Eden空间、From Survivor 空间、To Survivor空间,
【4】Java 堆处于物理上不连续的内存空间中。可以通过设定 -Xmx 和 -Xms设定jvm内存大小
5、方法区
【1】、多个线程共享内存区域,用于存储已被虚拟机加载的类信息、静态变量,及时编译器后的代码。
【2】、垃圾收集行为在这个区域是比较少出现的
6、运行时常量池(-XX:PermSize -XX:MaxPremSize)
【1】、是方法区的一个部分,.class文件中除了有类的版本、字段、方法、接口等信息外,
还有常量池用于存放编译期生成的各种字面量的符号引用,这部分内容将在类加载后存放到方法区的运行时常量池,可以在运行期间将常量放入池中。
7、本机内存(-XX:MaxDirectMemorySize指定。)如果不指定那就是默认和java堆的最大值一样(-Mmx)
java.lang.OutOfMemoryError
java垃圾回收知识点
垃圾回收判断
判断对象已死根据引用计数算法是不行的,因为如果两个对象相互引用那么他们的计数就不可能为0, 根据可达性分析算法,如果一个对象无法到达其GC ROOTs时候,则可以判断这个对象为可回收对象, 可作为GC ROOTS的对象有 方法区中静态属性引用的对象和常量引用的对象,还有虚拟机栈中引用的对象和本地方法栈引用的对象 一个对象的死亡会经历两次标记,如果对象在进行可达性分析后没有与GC ROOTS相连接的引用链,会进行第一次标记和进行 一次刷选, 刷选的条件就是此对象是否有必要执行finalize()方法,当对象没有重写finalize()或者finalize()方法已经被 执行过了,这就没必要执行刷选了。如果对象在finalize()方法里面重写与引用链上的对象关联,就不会被回收。 如果对象没有必要执行finalize()则这些对象会放到F-quenen队列中,由虚拟机去触发执行 然后进行第二次标记垃圾收集算法
标记-清除算法:标率低,会有不连续的内存碎片 复制算法:将内存分成一半,代价就是内存缩下一半了,如果对象存活率较高就需要进行过多的复制操作 标记-整理算法: 和标记清除算法类似 分代收集算法:新生代使用复制算法,老年代因为对象存活高使用标记-清理或者标记-整理算法垃圾收集器
新生代: Serial收集器:单线程的 ParNew收集器:多线程的 CMS收集器:并发收集、低停顿 一般互联网网站使用多,重视服务响应速度, 收集的时候是一种以最短回收停顿时间为目标的收集器,是基于“标记-清除”算法实现的 G1收集器:
虚拟机类加载机制
类的生命周期
加载-》【验证->准备->解析】(可以合并为连接)-》初始化=》使用=》卸载类必须要进行初始化
1、遇到new,getstatic等字节码指令。生成这些字节码的java 场景有new关键字,设置一个类的静态子段。 2、利用reflect方法对类进行反射调用。 3、当初始化一个类,如果父类没初始化,首先初始化父类 4、虚拟机启动时候,需要指定一个要执行的类,也就是main方法。加载
1、通过类名去获取定义此类的二进制字节流。 2、将这个字节流所代表的静态存储结构转换成运行时方法区的数据结构。 3、在java堆中生成代表这个类的对象,作为方法区这些参数访问的入口。验证
1、文件格式验证,是否以魔数开头,主版本是否在当前虚拟机处理范围内。 2、元数据验证 3、字节码验证 4、符号引用验证准备
为类变量分配内存,并设置类变量初始值。(static修饰的变量)例如给int赋值0解析
类和接口的解析、字段解析、类方法解析、接口方法解析初始化
调用static{}方法,如果有父类的话会先调用父类的static方法类的加载器
双亲委派模型:是为了安全考虑而设计的 某个特定的类加载器在接到加载类的请求时,首先将加载任务委托给父类加载器,依次递归, 如果父类加载器可以完成类加载任务,就成功返回;只有父类加载器无法完成此加载任务时,才自己去加载。 加载器有 启动类加载器(bootstarp classLoader)==> 扩展类加载器(Extension ClassLoader)==>应用程序加载器(Application ClassLoader)==>自定义类加载器 启动(Bootstrap)类加载器:是用本地代码实现的类装入器,它负责将 <Java_Runtime_Home>/lib下面的类库加载到内存中(比如rt.jar)。 由于引导类加载器涉及到虚拟机本地实现细节,开发者无法直接获取到启动类加载器的引用,所以不允许直接通过引用进行操作。 标准扩展(Extension)类加载器:是由 Sun 的 ExtClassLoader(sun.misc.Launcher$ExtClassLoader)实现的。 它负责将< Java_Runtime_Home >/lib/ext或者由系统变量 java.ext.dir指定位置中的类库加载到内存中。 系统(System)类加载器:是由 Sun 的 AppClassLoader(sun.misc.Launcher$AppClassLoader)实现的。 它负责将系统类路径(CLASSPATH)中指定的类库加载到内存中。
早期编译器优化
泛型与类型擦除
泛型的代码通过反编译后查看编译后的字节码,所有的类型都变成了原生类型,并且在相应的地方进行强制转换自动装箱、拆箱与遍历循环
遍历循环会变成迭代器实现方式 int方法会自动装箱变成integerjava内存模型
java多线程会出现线程安全的问题,而可见性是由java的内存模型决定的,因为每个线程都有一个私有的本地内存, 同时也会导致共享变量竞争的问题。 java线程->工作内存-》(save和load操作)-》主内存 java线程->工作内存-》(save和load操作)-》主内存 java线程->工作内存-》(save和load操作)-》主内存 java线程->工作内存-》(save和load操作)-》主内存 java内存操作指令: lock/unlock/read/write 主内存 load/user/assign/store 工作内存 read and load 从主存赋值变量到工作内存 user and assign 执行代码和改变共享变量(可能出现多次) store and write 写到工作内存,同时拷贝到主内存并发编程三个概念
原子性:一个操作要么全部执行,并且执行过程中不被打断,要么不执行。synchronized和java.util.concurrent包中的锁都能够保证操作的原子性
synchronized和Lock能够保证任一时刻只有一个线程执行该代码块,那么自然就不存在原子性问题了,从而保证了原子性
可见性:多个线程对变量操作之后,别的线程可以立即感知到。volatile,synchronized和Lock也能够保证可见性有序性:在Java内存模型中,允许编译器和处理器对指令进行重排序,但是重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。
防止指令重排序,它只会对不存在数据依赖性的指令进行重排序,编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的
两个操作的执行顺序,synchronized和Lock来保证有序性,volatile禁止重排序
volatile关键字通过提供“内存屏障”的方式来防止指令被重排序,为了实现volatile的内存语义,编译器在生成字节码时,
会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
指令重排序
happens-before原则(先行发生原则)
程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作
锁定规则:一个unLock操作先行发生于后面对同一个锁额lock操作
volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作
传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C
20170622-transient关键字
transient 修饰的变量都不参与序列化,当反序列化的时候所有transient 修饰的成员变量字段值都是null
20170622-数据库复习
事物隔离级别
数据库事务的隔离级别有4个,由低到高依次为Read uncommitted、Read committed、Repeatable read、Serializable,
这四个级别可以逐个解决脏读、不可重复读、幻读这几类问题。
读未提交(会出现脏读、重复读、幻读)、读已提交(会出现重复读、幻读)、重复读(会出现幻读)、序列化
读未提交场景:A、B同时开启事物,A修改数据但没提交,B这时候读取到A修改的数据继续后面的操作,
但是如果A事物回滚了,就会导致B读取到的脏数据
读已提交:可以解决脏读的情况,但是会有重复读的情况
大多数数据库的默认级别就是Read committed。
重复读:A、B同时开启事物,A将某表字段值从1000修改成500 ,但是还没提交事物,B这时候读取到是1000,这时候
A再提交事物,B再重新读取该字段,发现值变成了500,这就会导致重复读的情况了。这是MySQL的默认事务隔离级别。
如果将事物级别设置成重复读,在同一个事务内的查询都是事务开始时刻一致的,也就是无论查询多少次值都是一样的,
也就可以解决重复读的情况
幻读情况:虽然数据库事物级别设置成重复读,但是如果会出现幻读的情况 比如A事物执行select * from table,返回了
5条数据,这时候另外一个操作往这个表里面添加一条数据,再次执行select * from table,发现返回了6条数据,这就是
幻读的情况!
死锁情况
select * from information_schema.innodb_locks
1、不同表相同记录行锁冲突(事务A和事务B操作两张表,但出现循环等待锁情况)
2、相同表相同记录行 (比如两个job在执行数据批量更新时,jobA处理的的id列表为[1,2,3,4],
而job处理的id列表为[8,9,10,4,2],例如2这条记录两边都出现这样就造成了死锁。)
3、不同索引锁冲突(事务A在执行时,除了在二级索引加锁外,还会在聚簇索引上加锁,
在聚簇索引上加锁的顺序是[1,4,2,3,5],而事务B执行时,只在聚簇索引上加锁,加锁顺序是[1,2,3,4,5],这样就造成了死锁的可能性。)
比如 update table where id>1 和 update table where id=2 会导致死锁
4、gap锁冲突
CREATE TABLE `test` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(100) DEFAULT NULL,
`sex` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `ix_name` (`name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=24 DEFAULT CHARSET=utf8mb4;
INSERT INTO `test` VALUES (1, 'gao', 1);
INSERT INTO `test` VALUES (2, 'guang', 2);
INSERT INTO `test` VALUES (3, 'jin', 3);
INSERT INTO `test` VALUES (4, 'zhang', 4);
-- Session 1 执行不提及
begin;
UPDATE test set name="t" where name="guang";
--Session2 执行会被block
begin;
INSERT INTO `pig`.`test`( `name`, `sex`) VALUES ( 'gao2', 4);
COMMIT;
因为 事物A会对 非聚簇索引的记录"guang"加上行级别锁(X)
事物B因为是插入操作,所以会先判断是否有和插入意向锁冲突的锁,如果有就加插入意向锁,(X,GAP)然后等待,
如果没有,就直接写数据。
锁与索引关系
如果操作的是非聚簇索引,会先对非聚簇索引加锁,再对主键索引加锁
如果操作对是聚簇索引,就直接对主键索引加锁
如果操作的记录没有索引,则对表加锁
锁与隔离级别的关系
RR隔离级别,增加gap锁
spring事物传播特性
PROPAGATION_REQUIRED :用的最多的,如果当前方法没有事物那就先建立一个事物,如果有,那就加入到这个事物。
PROPAGATION_SUPPORTS :支持当前事务,如果当前没有事务,就以非事务方式执行。
PROPAGATION_MANDATORY 使用当前的事务,如果当前没有事务,就抛出异常。
PROPAGATION_REQUIRES_NEW 新建事务,如果当前存在事务,把当前事务挂起。
PROPAGATION_NOT_SUPPORTED 以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
PROPAGATION_NEVER 以非事务方式执行,如果当前存在事务,则抛出异常。
PROPAGATION_NESTED 如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与 PROPAGATION_REQUIRED 类似的操作
20170622-动态代理
底层原理:
都是在代理类目录生成一个**$**.class带有$的代理编译后的类,调用的时候就是调用这个代理类
spring aop使用的有jdk和cglib,jdk创建代理对象的时间比cglib短,但是代理方法的执行时间比cglib慢
如果spring里面用到的对象单例模式的比较多,就建议使用cglib模式,虽然启动时间会长点,但是提高程序效率
dubbo里面使用较多的就是javassist代理,因为有时候不需要代理整个类,只用代理某个方法
jdk动态代理
针对接口进行代理的,不可以对普通类进行代理
核心代码:
InterfaceInvocationHandler implements InvocationHandler{
public Object invoke(Object object, Method method, Object[] objects){}
}
Interface jdkProxy = (Interface) Proxy.newProxyInstance(ClassLoader.getSystemClassLoader(),
new Class[] { Interface.class }, new InterfaceInvocationHandler(interfaceImp))
cglib
针对类进行代理的,比较自由
核心代码:
Enhancer enhancer = new Enhancer();
enhancer.setCallback(new CglibInterceptor(delegate));
enhancer.setInterfaces(new Class[] { CountService.class });
CountService cglibProxy = (CountService) enhancer.create();
class CglibInterceptor implements MethodInterceptor {
public Object intercept(Object object, Method method,
Object[] objects,MethodProxy methodProxy) throws Throwable {
}
JAVAASSIST字节码
只需用字符串拼接出Java源码,便可生成相应字节码
20170703-for each原理和java迭代注意
总结
For-each语法内部,对collection是用nested iteratoration来实现的,对数组是用下标遍历来实现。
注意
对于集合尽量不要用for each 因为本质都是转换成iterator
LinkedHashMap 不要在迭代器iterator里面使用get方法,因为get()方法会修改LinkedHashMap中的链表结构,
以便将最近访问的元素放置到链表的末尾
在集合内部维护一个字段modCount用于记录集合被修改的次数,每当集合内部结构发生变化(add,remove,set)时,modCount+1。
List在迭代器内部也维护一个字段expectedModCount,同样记录当前集合修改的次数,初始化为集合的modCount值。
当我们在调用Iterator进行遍历操作时,如果有其他线程修改list会出现modCount!=expectedModCount的情况,
就会报并发修改异常java.util.ConcurrentModificationException。
for each对象
List<Integer> list = new ArrayList<>();
list.add(1);
for (Integer i : list) {
System.out.println("" + i);
}
通过编译后的字节码,虚拟机将以上代码转换成了迭代器
INVOKEINTERFACE java/util/List.iterator ()Ljava/util/Iterator;
FRAME APPEND [java/util/List java/util/Iterator]
INVOKEINTERFACE java/util/Iterator.hasNext ()Z
INVOKEINTERFACE java/util/Iterator.next ()Ljava/lang/Object;
20170704-linux线程gc查询
jstat -gc pid 250 4 //每隔250ms 打印四次Java垃圾回收详情
jstat -gc pid 250 //每隔250ms 打印Java垃圾回收详情
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
6080.0 6080.0 0.0 3014.3 48640.0 22188.1 121148.0 62950.3 62720.0 61800.1 7936.0 7742.1 277 1.328 6 0.784 2.111
6080.0 6080.0 0.0 3014.3 48640.0 22190.5 121148.0 62950.3 62720.0 61800.1 7936.0 7742.1 277 1.328 6 0.784 2.111
S0C、S1C、S0U、S1U:Survivor 0/1区容量(Capacity)和使用量(Used)
EC、EU:Eden区容量和使用量
OC、OU:年老代容量和使用量
PC、PU:永久代容量和使用量
YGC、YGT:年轻代GC次数和GC耗时
FGC、FGCT:Full GC次数和Full GC耗时
GCT:GC总耗时
20170705-java对象的强、软、弱、虚引用
强引用:垃圾回收期不会主动去回收,哪怕Java虚拟机报OutOfMemoryError
软引用:当Java堆内存不够的时候,才会进行回收 (没有任何强引用关联),例如缓存系统
弱引用:比软引用更容易被回收,当垃圾回收期线程执行的时候,不管当前堆内存是否够,都会回收(没有任何强引用关联)
在垃圾回收时,如果这个对象只被关联(没有任何强引用关联),那么这个对象就会被回收
不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。
ThreadLocal原理与内存泄露
ThreadLocal为每一个线程创建的单独变量副本,底层是有ThreadLocal.ThreadLocalMap去维护的,每一个
线程都有一个独立的ThreadLocalMap,ThreadLocal实例就是map对应的key。
例如set的时候,首先获取当前线程的ThreadLocalMap 然后再放值。
ThreadLocalMap的key是弱引用,当我们吧threadLocal置为null时候,thread会被gc,
但是value缺不会被回收,因为还有value还有强引用,只有当当前thread结束后,value
才会被回收。比如我们使用线程池的时候,Thread是不会被回收的,所以就会发生内存泄露的。
最好的方法就是手动调用remove();
20170706-设计模式回顾
单例模式
懒汉、饿汉、doublecheck、匿名类
工厂模式
简单工厂:例如获取jdbc的方式
工厂方法模式:父类定义抽象接口,子类负责生成具体的对象,将类的实例化操作延迟到子类。
抽象工厂模式:抽象工厂模式提供一个创建一系列相关或相互依赖对象的接口,而无须指定他们具体的类。
它针对的是有多个产品的等级结构。而工厂方法模式针对的是一个产品的等级结构。
在只有一个产品族的情况下,抽象工厂模式实际上退化到工厂方法模式
装饰模式
例如 io流 new FileInputStream(new File())
代理模式
例如jdk的动态代理
命令模式
将一个请求封装成一个对象,从而使您可以用不同的请求对客户进行参数化
策略模式
定义一系列的算法,把它们一个个封装起来, 并且使它们可相互替换
迭代模式
list迭代器
观察者模式
spring 里面用到了ApplicationEvent 和ApplicationListener,
applicationContext.publishEvent(Event);
观察者订阅,订阅者发生变动时候通知所有观察者。
适配器模式
当第三方定义好了接口AInterface,但是并没有给具体的实现,我们就可以定义一个适配类Adapter,
适配器类也实现了AInterface的所有方法。
AInterfaceImp extends Adapter implement AInterface{
method (){
super.method();
}
}
20170707-通过Java字节码去看原理
idea 可以安装ASM ByteCode 插件直接查看编译后的字节码
将一个局部变量加载到操纵栈的指令包括:iload、iload_、lload…
将一个数值从操作数栈存储到局部变量表的指令包括:istore、istore_、lstore…
一般都是先将局部变量加载到操作数栈,然后对操作数栈这个数据进行处理后再
将操作数栈的数据存储到局部变量表
i++与++i的原理
①int i = 0; ②int i = 0; 3、int i = 0;
i = i++; i = ++i; i++
对应的字节码。
①iconst_0 ②iconst_0
istore_1 istore_1
iload_1 iinc 1,1 该命令给局部变量表的1号位置的int值增加1
iinc 1,1 iload_1
istore_1 istore_1
①虽然都有 iinc 1,1的操作,但是1在自增后没有将局部变量i自增后的值load到操作数栈(缺少 iload_1命令),
导致自增的值被istore_1 原来操作数栈0的值给覆盖了。
2与3的效果作用一样,都是包含iload的操作
for each的处理
For-each语法内部,对collection是用nested iteratoration来实现的,对数组是用下标遍历来实现。
装箱与拆箱
Integer i = 10;
int n = i;
对应的字节码:装箱的时候是用到包装类的valueof(),拆箱时候用到的是包装类的intValue();
INVOKESTATIC java/lang/Integer.valueOf (I)Ljava/lang/Integer;
INVOKEVIRTUAL java/lang/Integer.intValue ()
Integer包装类在加载的时候会初始化-128到127的缓存对象值,所以比较==的时候需要注意。
泛型
List<String> list=new ArrayList<>();
list.add("1");
String a=list.get(1);
对应字节码:没有一点泛型的信息。
INVOKEINTERFACE java/util/List.add (Ljava/lang/Object;)Z
ALOAD 0
ICONST_1
INVOKEINTERFACE java/util/List.get (I)Ljava/lang/Object;
CHECKCAST java/lang/String
ASTORE 1
java泛型的实现原理是类型擦除。Java的泛型是伪泛型。在编译期间,所有的泛型信息都会被擦除掉。
JAVA的泛型只是一个语法糖,实际上在运行时还是有类型转换的过程,从JVM生成的代码来看,
和传递一个Object(或者extends的类型)没什么区别。当然泛型的最大好处是编绎期的类型错误检查
20170711-linux常用命令复习
文件权限
例如 777 rwx rwx rwx
从左至右,1-3位数字代表文件所有者的权限,4-6位数字代表同组用户的权限,7-9数字代表其他用户的权限。
r=4,w=2,x=1
ls -lrt /usr/bin/java 查看路径
20170712-QPS和TPS
qps:是一台服务器每秒能够相应的查询次数
单机QPS的上限是多少呢?
说到单机,你必须明确指出硬性指标,CPU、内存、硬盘、带宽等
TPS:一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程(一个tps里面可能包含多个tps)
2C 4G机器单机一般1000QPS。
8C 8G机器单机可承受7000QPS。
并发估算法:
C:并发
n:压测时间段内所有的请求数
L:平均响应时间
T:压测总时长
C = nL / T
这里注意:L(平均响应时间)≠ T(总时长)/ n(总请求)
例如 100个请求,每个耗时1s,压测阶段总共耗费10s
那么并发数 10=100*1s/10s
qps计算公式:
公式1: qps=并发数/平均响应时间
公式2: qps=请求总数/总时长
C = nL / T 推导出 公式1=等于公式2
并发 = 请求总数*平均响应时间 / 总时长
=》并发 / 平均响应时间 = 请求总数 / 总时长
=》公式1 = 公式2
实际压测时,两个公式还是会有些微差别,这就是因为我们本来预想并发应该=工具线程数
但是压测过程中,实际并发发生了变化,实际并发确实稍低于工具线程数
1、在单接口压测时,我们用“请求总数/总时长”得到吞吐量;
然后再用“吞吐量/平均响应时间”得到实际并发,此举可用来观察系统实际承受的并发
qps是需要压测才可以评估出来,例如在指定时间,不同线程数,压测接口,根据公式2就可以推算出来
http接口可以用jmeter直接去测试
rpc接口可以用JMH性能测试
参考:https://www.xmeter.net/wordpress/?p=152
20170712-系统容量预估方法
pv计算带宽:带宽和并发数量有关
【步骤一:评估总访问量】 -> 询问业务、产品、运营
【步骤二:评估平均访问量QPS】-> 除以时间,一天算4w秒
【步骤三:评估高峰QPS】 -> 根据业务曲线图来,获取高峰qps
【步骤四:评估系统、单机极限QPS】 -> 压测很重要 获取单机最高qps
【步骤五:根据线上冗余度回答两个问题】 -> 估计冗余度与线上冗余度差值
原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间
公式:( 总PV数 80% ) / ( 每天秒数 20% ) = 峰值时间每秒请求数(QPS)
机器:峰值时间每秒QPS / 单台机器的QPS = 需要的机器
例子:每天300w PV 的在单台机器上,这台机器需要多少QPS?
( 3000000 0.8 ) / (86400 0.2 ) = 139 (QPS)
例子:如果一台机器的QPS是58,需要几台机器来支持?
139 / 58 = 3
20170713-TCP/IP相关
HTTPS
https://zhuanlan.zhihu.com/p/31477508
https使用对称加密+非对称加密+CA(赛门铁克CA)认证 三个技术合并到一起,才保证数据传输的安全。
首先使用RSA算法生产一对秘钥 K1和K2,K1是公钥,k2是秘钥,K1加密后的数据必须要K2才可以解密。
服务端发送K1到目的地,然后目的地在生成一个用来对称加密传输的秘钥K3,然后再用k1就加密k3
再传输给服务端,服务端再用k2去解密得到秘钥k3,这样双方就可以进行aes对称加密算法进行传输
1.Client发起一个HTTPS(比如https://juejin.im/user/5a9a9cdcf265da238b7d771c)的请求,根据RFC2818的规定,Client知道需要连接Server的443(默认)端口。
2.Server把事先配置好的公钥证书(public key certificate)返回给客户端。
3.Client验证公钥证书:比如是否在有效期内,证书的用途是不是匹配Client请求的站点,是不是在CRL吊销列表里面,它的上一级证书是否有效,这是一个递归的过程,直到验证到根证书(操作系统内置的Root证书或者Client内置的Root证书)。如果验证通过则继续,不通过则显示警告信息。
4.Client使用伪随机数生成器生成加密所使用的对称密钥,然后用证书的公钥加密这个对称密钥,发给Server。
5.Server使用自己的私钥(private key)解密这个消息,得到对称密钥。至此,Client和Server双方都持有了相同的对称密钥。
6.Server使用对称密钥加密“明文内容A”,发送给Client。
7.Client使用对称密钥解密响应的密文,得到“明文内容A”。
8.Client再次发起HTTPS的请求,使用对称密钥加密请求的“明文内容B”,然后Server使用对称密钥解密密文,得到“明文内容B”。
ssh免密登陆原理
首先客户端生成公钥与私钥, 同时将公钥拷贝到服务端上。当客户端请求服务端时候,会先进行公钥比较,
服务器端会用公钥加密"质询"给客户端,客户端收到质询后再用私钥解密,然后发给服务器。
http状态码
200 - 服务器成功返回网页
404 - 请求的网页不存在
503 - 服务器超时
3xx -重定向
OSI七层模型
应用层:应用软件使用的协议,例如pop3/smtp/http协议
表示层: 决定数据的展现方式,比如图片可以是jpeg/bmp/png
会话层:为两端通信实体建立连接
传输层:将数据分成很多小段,进行传输
网络层:路由选择,选择通信使用协议http,ftp ,指定路由策略
数据链路层:根据端口与MAC地址,做分组(VLAN)隔离、端口安全、访问控制。
物理层:将数据最终编码为用0、1标识的比特流,然后传输
TCP/IP四层模型
应用层:
FTP、DNS、HTTP协议
可以对应osi的应用层、表示层、会话层。
传输层:tcp与udp协议
网络层:
链路层:硬件部分如 网卡、光纤
TCP数据段格式
顺序号字段:Seq序号,用来标识从TCP源端向目的端发送的字节流,发起方发送数据时对此进行标记。
确认号字段:只有ACK标志为1时,确认号字段才有效。
SYN:发起一个连接
ACK:确认序号有效
FIN:释放一个连接
需要注意的是:
(A)不要将确认序号ACK与标志位中的ack搞混了。
(B)确认方Ack=发起方seq+1,两端配对。
tcp三次握手
TCP A TCP B
1. CLOSED LISTEN
2. SYN-SENT --> <SEQ=100><CTL=SYN> ...
3. (duplicate) ... <SEQ=90><CTL=SYN> --> SYN-RECEIVED
4. SYN-SENT <-- <SEQ=300><ACK=91><CTL=SYN,ACK> <-- SYN-RECEIVED
5. SYN-SENT --> <SEQ=91><CTL=RST> --> LISTEN
6. ... <SEQ=100><CTL=SYN> --> SYN-RECEIVED
7. SYN-SENT <-- <SEQ=400><ACK=101><CTL=SYN,ACK> <-- SYN-RECEIVED
8. ESTABLISHED --> <SEQ=101><ACK=401><CTL=ACK> --> ESTABLISHED
1、客户端向服务端发送syn包,并且告诉服务器端当前发送序号为seq=j,客户端进入sync_sent
2、服务端收到包后 进行ACK=j+1应答,同时也向客户端发送syn包 同时告诉客户端当前发送序号为seq=k,服务器进入sync_rcvd
3、客户端收到ack后检查ack是否为j+1,同时客户端因为发送应答包确认序号 ack=k+1,客户端进入established
4、服务端收到应答包后,检查ack是否为j+1,如果是就进入established
四次挥手
主动关闭流程,客户端先发起申请
第一次挥手:client端发送FIN,用来关闭client到server端的数据传输,client进入fin_wait_!状态。
第二次挥手:server端收到FIN后,发送一个ACK到client端,确认序号为收到序号+1,server进入close_wait状态
第三次挥手:server发送一个FIN,用来关闭server到client的数据传输,server进入last_ack状态
第四次挥手:client收到FIN,client进入TIME_WAIT状态,接着发送一个ACK给server 确认序号为收到序号+1,
server进入closed状态,完成四次挥手。
为什么建立连接是三次握手,而关闭连接却是四次挥手呢
首先三次握手是为了确保客户端和服务端都能收到彼此的数据包
服务端在LISTEN状态下,收到建立连接请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。
而关闭连接时,客户端和服务端都有"发送"与"接收"都功能。
如果ack与fin一起发过去,此时server端可能还有数据没发送完,所以需要分开。
当收到对方的FIN报文时,仅仅表示对方不再发送数据了但是还能接收数据,己方也未必全部数据都发送给对方了,
所以己方可以立即close,也可以发送一些数据给对方后,再发送FIN报文给对方来表示同意现在关闭连接,
因此,己方ACK和FIN一般都会分开发送。通俗说就是挥手的时候是server端先发送ACK 然后再发送FIN
syn攻击
在三次握手过程中,Server发送SYN-ACK之后,收到Client的ACK之前的TCP连接称为半连接(half-open connect),此时Server处于SYN_RCVD状态,
当收到ACK后,Server转入ESTABLISHED状态。SYN攻击就是Client在短时间内伪造大量不存在的IP地址,并向Server不断地发送SYN包,
Server回复确认包,并等待Client的确认,由于源地址是不存在的,因此,Server需要不断重发直至超时,
这些伪造的SYN包将长时间占用未连接队列,导致正常的SYN请求因为队列满而被丢弃,从而引起网络堵塞甚至系统瘫痪。
SYN攻击时一种典型的DDOS攻击,检测SYN攻击的方式非常简单,即当Server上有大量半连接状态且源IP地址是随机的,则可以断定遭到SYN攻击了,
使用如下命令可以让之现行:
#netstat -nap | grep SYN_RECV
与http相关协议
ip协议:使用 ARP 协议凭借 MAC 地址进行通信
tcp协议:TCP 协议为了更容易传送大数据才把数据分割,而且 TCP 协议能够确认数据最终是否送达到对,
为了确保信息能够确保准确无误的到达,TCP采用了著名的三次握手策略.
dns:DNS(Domain names System) 和HTTP协议一样是处于应用层的服务,提供域名到IP地址之间的解析服务
time_wait与close_wait
服务器在处理客户端请求的时候,如果你的程序设计为服务器主动关闭,那么你才有可能需要关注这个TIMEWAIT状态过多的问题。
如果你的服务器设计为被动关闭,那么你首先要关注的是CLOSE_WAIT。
time_wait
主动正常关闭TCP连接,都会出现TIMEWAIT。
在高并发短连接的TCP服务器上,当服务器处理完请求后立刻按照主动正常关闭连接这个场景下,会出现大量socket处于TIMEWAIT状态。
如果客户端的并发量持续很高,此时部分客户端就会显示连接不上
高并发可以让服务器在短时间范围内同时占用大量端口,而端口有个0~65535的范围,并不是很多,刨除系统和其他服务要用的,剩下的就更少了。
如何尽量处理TIMEWAIT过多
linux没有在sysctl或者proc文件系统暴露修改这个TIMEWAIT超时时间的接口,可以修改内核协议栈代码中关于这个TIMEWAIT的超时时间参数,重编内核,让它缩短超时时间,加快回收
sysctl改两个内核参数就行了,如下:
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
close_wait
服务器A是一台爬虫服务器,它使用简单的HttpClient去请求资源服务器B上面的apache获取文件资源,
正常情况下,如果请求成功,那么在抓取完资源后,服务器A会主动发出关闭连接的请求,这个时候就是主动关闭连接,
服务器A的连接状态我们可以看到是TIME_WAIT。
如果一旦发生异常呢?假设请求的资源服务器B上并不存在,那么这个时候就会由服务器B发出关闭连接的请求,服务器A就是被动的关闭了连接,
如果服务器A被动关闭异常的时候程序员忘了HttpClient释放连接,造成服务器A出现大量CLOSE_WAIT。
如果这时候再有其他客户端 访问服务器A去触发爬虫,这时候因为服务器A的连接数已经使用完了,会导致客户端超时,主动关闭连接
这时候,服务器A也会造成大量的CLOSE_WAIT
closewait只会出现在被动关闭的服务器上,服务器因为某种异常导致连接数被打满,在客户端发出fin时候,服务端虽然回复了ack,但是
因为请求的线程或者连接还在阻塞阶段,无法继续回复,导致服务端一直处于closewait阶段。
两种场景:
https://www.cnblogs.com/grey-wolf/p/9945637.html
https://blog.csdn.net/yu616568/article/details/44677985
tcp粘包、拆包
客户端和服务器建立一个连接,客户端连续发送两条消息,客户端关闭与服务端的连接。
如果服务端只收到一个数据包,这个数据包包含客户端的两条消息,这时候就发生了TCP粘包。
如果服务端收到两个数据包,第一个数据包包含数据的一部分,第二个数据包包含第一台消息的后半部分和第二条消息,这时候就发生TCP拆包
发生TCP粘包、拆包主要是由于下面一些原因:
1、应用程序写入的数据大于套接字缓冲区大小,这将会发生拆包。
2、应用程序写入数据小于套接字缓冲区大小,网卡将应用多次写入的数据发送到网络上,这将会发生粘包。
3、进行MSS(最大报文长度)大小的TCP分段,当TCP报文长度-TCP头部长度>MSS的时候将发生拆包。
4、接收方法不及时读取套接字缓冲区数据,这将发生粘包。
如何处理粘包、拆包问题:
使用带消息头的协议、消息头存储消息开始标识及消息长度信息,服务端获取消息头的时候解析出消息长度,然后向后读取该长度的内容。
设置定长消息,服务端每次读取既定长度的内容作为一条完整消息。
设置消息边界,服务端从网络流中按消息编辑分离出消息内容。
如何提高单机短连接QPS
http://weibo.com/ttarticle/p/show?id=2309404037884855362229
tcp应该有客户端发起连接关闭,默认情况下客户端关闭TCP连接后本地的临时端口
会进入time_wait状态,这对qps提升有很大限制
增加临时端口的数量,增加可被消耗的临时端口资源
sysctl -w "net.ipv4.ip_local_port_range=1024 65535”
第一种方法是启用tw_reuse,tw_reuse能加速TIME_WAIT状态端口在几秒时间内安全的回收
sysctl -w net.ipv4.tcp_timestamps=1
sysctl -w net.ipv4.tcp_tw_reuse=1
2.6.32内核下启动tw_reuse短连接可以达到2w,性能并不稳定;
第二种方法更激进些,启用tw_recycle,tw_recycle允许在两个RTT。当多个客户端处于NAT后时,
在服务器端开启tw_recycle会引起丢包问题,如果丢SYN包,就会造成新建连接失败
sysctl -w net.ipv4.tcp_timestamps=1
sysctl -w net.ipv4.tcp_tw_recycle=1
2.6.32内核下启动tw_recycle短连接可以达到6w,比较稳定;
/etc/sysctl.conf
#对于一个新建连接,内核要发送多少个 SYN 连接请求才决定放弃,不应该大于255,默认值是5,对应于180秒左右时间
net.ipv4.tcp_syn_retries=2
#net.ipv4.tcp_synack_retries=2
#表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时,改为300秒
net.ipv4.tcp_keepalive_time=1200
net.ipv4.tcp_orphan_retries=3
#表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间
net.ipv4.tcp_fin_timeout=30
#表示SYN队列的长度,默认为1024,加大队列长度为8192,可以容纳更多等待连接的网络连接数。
net.ipv4.tcp_max_syn_backlog = 4096
#表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭
net.ipv4.tcp_syncookies = 1
#表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭
net.ipv4.tcp_tw_reuse = 1
#表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭
net.ipv4.tcp_tw_recycle = 1
##减少超时前的探测次数
net.ipv4.tcp_keepalive_probes=5
##优化网络设备接收队列
net.core.netdev_max_backlog=3000
修改完之后执行/sbin/sysctl -p让参数生效。
这里头主要注意到的是net.ipv4.tcp_tw_reuse
net.ipv4.tcp_tw_recycle
net.ipv4.tcp_fin_timeout
net.ipv4.tcp_keepalive_*
这几个参数。
net.ipv4.tcp_tw_reuse和net.ipv4.tcp_tw_recycle的开启都是为了回收处于TIME_WAIT状态的资源。
net.ipv4.tcp_fin_timeout这个时间可以减少在异常情况下服务器从FIN-WAIT-2转到TIME_WAIT的时间。
net.ipv4.tcp_keepalive_*一系列参数,是用来设置服务器检测连接存活的相关配置。
20170714-mysql相关
优化
1. 优化更需要优化的Query;
2. 定位优化对象的性能瓶颈;
3. 明确的优化目标;
4. 从Explain 入手;
5. 多使用profile
6. 永远用小结果集驱动大的结果集;
7. 尽可能在索引中完成排序;
8. 只取出自己需要的Columns;
9. 仅仅使用最有效的过滤条件;
10. 尽可能避免复杂的Join 和子查询;
索引失效
1. MyISAM 存储引擎索引键长度总和不能超过1000 字节;
2. BLOB 和TEXT 类型的列只能创建前缀索引;
3. MySQL 目前不支持函数索引;
4. 使用不等于(!= 或者<>)的时候MySQL 无法使用索引;
5. 过滤字段使用了函数运算后(如abs(column)),MySQL 无法使用索引;
6. Join 语句中Join 条件字段类型不一致的时候MySQL 无法使用索引;
7. 使用LIKE 操作的时候如果条件以通配符开始( '%abc...')MySQL 无法使用索引;
8. 使用非等值查询的时候MySQL 无法使用Hash 索引;
9. 某字段类型为varchar类型,根据查询关键字段查询时,写入值为Int类型,导致无法命中索引
10.查询条件左边写入函数,导致无法命中索引
10条SQL技巧
1.负向条件查询不能使用索引
select * from order where status!=0 and stauts!=1
not in/not exists/<> 都不行
可以优化为in查询:
select * from order where status in(2,3)
2.前导模糊查询不能使用索引
select * from order where desc like '%XX'
而非前导模糊查询则可以:
select * from order where desc like 'XX%'
3.数据区分度不大的字段不宜使用索引
select * from user where sex=1
原因:性别只有男,女,每次过滤掉的数据很少,不宜使用索引。
经验上,能过滤80%数据时就可以使用索引。
对于订单状态,如果状态值很少,不宜使用索引,如果状态值很多,能够过滤大量数据,则应该建立索引。
4.在属性上进行计算不能命中索引
select * from order where YEAR(date) < = '2017'
可以改成属性右边的函数
select * from order where date < = CURDATE()
或者:
select * from order where date < = '2017-01-01'
5.允许为null的列,查询有潜在大坑(特别注意)
单列索引不存null值,复合索引不存全为null的值,如果列允许为null,可能会得到“不符合预期”的结果集
select * from user where name != 'shenjian'
如果name允许为null,索引不存储null值,结果集中不会包含这些记录,会导致查询的结果缺少结果集
6.复合索引最左前缀,并不是值SQL语句的where顺序要和复合索引一致
7.如果明确知道只有一条结果返回,limit 1能够提高效率
select * from user where login_name=?
可以优化为:
select * from user where login_name=? limit 1
你知道只有一条结果,但数据库并不知道,明确告诉它,让它主动停止游标移动
8.把计算放到业务层而不是数据库层,除了节省数据的CPU,还有意想不到的查询缓存优化效果
释放了数据库的CPU
多次调用,传入的SQL相同,才可以利用查询缓存
9.强制类型转换会全表扫描
select * from user where phone=13800001234;
改成
select * from user where phone="13800001234";
索引
较频繁的作为查询条件的字段应该创建索引
唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件;
更新非常频繁的字段不适合创建索引
单键索引还是组合索引
聚簇索引
主键会默认创建聚簇索引,且一张表只允许存在一个聚簇索引
聚簇索引的叶子节点就是数据节点.
特点是存储数据的顺序和索引顺序一致
非聚簇索引
叶子节点仍然是索引节点,只不过有指向对应数据块的指针,索引表中的顺序通常与实际的页码顺序是不一致
联合索引
多个字段建立的索引,组合索引的第一个字段必须出现在查询组句中,不然会导致索引失效
比如组合索引create index index_a_b_c on table(a,b,c)
a|(a,b|b,a)|a,b,c等等 但是如果是 b,c索引就不会生效了。
最左前缀就是最左的索引列优先,b,a都会被数据库引擎优化成ab这种顺序,
左前缀索引
追加Index时,计算数据唯一性巧妙添加左前缀索引,提高索引命中率,保证索引字段唯一性
//以此算出城市拼音缩写长度为3时,命中率和唯一性比较高,则写下如下SQL:
例如 ALTER TABLE `city` ADD INDEX `index_on_pinyinInitial` USING BTREE (pinyin_initial(3));
explain参数分析
select_type:执行类型 simple为简单查询类型
type: const 标示查询结果最多匹配一行,查询很快,从最好到最差的连接类型为
const(常量查询)、eq_reg(使用唯一索引查找(主键或唯一索引))、ref(非唯一索引访问(只有普通索引))
、range(一般用于>= <= )、index和ALL(都全表扫描)
key: 实际使用的索引。如果为NULL,则没有使用索引
rows:MySQL认为必须检查的用来返回请求数据的行数
key_len的长度计算公式:
所有的索引字段,如果没有设置not null,则需要加一个字节。
定长字段,int占四个字节、date占三个字节、char(n)占n个字符。
对于变成字段varchar(n),则有n个字符+两个字节。
不同的字符集,一个字符占用的字节数不同。latin1编码的,一个字符占用一个字节,gbk编码的,
一个字符占用两个字节,utf8编码的,一个字符占用三个字节。
varchr(10)变长字段且允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)+1(NULL)+2(变长字段)
varchr(10)变长字段且不允许NULL = 10 *( character set:utf8=3,gbk=2,latin1=1)+2(变长字段)
char(10)固定字段且允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)+1(NULL)
char(10)固定字段且不允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)
20170715-springmvc相关
相关接口
BeanFactoryAware, 一般用于设置BeanFactory
BeanNameAware, 一般用于设置bean name
InitializingBean, 加载完之后调用afterPropertiesSet()
DisposableBean, 销毁之后调用destroy-method方法
ApplicationContextAware , 一般用于设置bean ApplicationContext
BeanFactoryPostProcessor ,
是针对于beanFactory的扩展点,即spring会在beanFactory初始化之后,
beanDefinition都已经loaded,但是bean还未创建前进行调用,可以修改,增加beanDefinition
BeanPostProcessor:
是针对bean的扩展点,即spring会在bean初始化前后 调用方法对bean进行处理
所有bean,在初始化之前调用postProcessBeforeInitialization,之后用postProcessAfterInitialization
如果一个类实现类BeanFactoryPostProcessor 那么该类初始化的时候是不会出现在postProcessBeforeInitialization
和postProcessAfterInitialization bean里面。
bean的加载顺序
1、
BeanFactoryPostProcessor是在spring容器加载了bean的定义文件之后,在bean实例化之前执行的
实现该接口,可以在spring的bean创建之前,修改bean的定义属性。
如果是当前类实现了BeanFactoryPostProcessor,那么会在afterPropertiesSet之后被调用
1、然后调用对象的构造方法,实例化
2、如果类实现了BeanNameAware 则调用setBeanName()
3、如果类实现了BeanPostProcessor 则调用postProcessBeforeInitialization
4、如果类实现了InitializingBean 则调用afterPropertiesSet()
5、如果指定了init方法也会调用
6、如果类实现了BeanPostProcessor 则调用postProcessAfterInitialization()
7、如果bean实现了ApplicationContextAware,则可以把上下文环境传过去。
8、如果累实现了DisposableBean 执行 destroy方法
如果我们在bean加载之后扩展这个bean,就可以通过BeanFactoryPostProcessor实现
通过postProcessBeforeInitialization和postProcessAfterInitialization
在bean加载之前或加载之后进行代理
url请求流程
1、用户发送url请求,然后请求被dispatchServlet拦截。
2、dispartchServlet解析url,根据url调用HandleMapping获取该handler配置的
相关拦截器,根据handler获取handlerAdapter调用controller里面的对应方法,
3,controller执行完后返回ModerAndView,然后视图解析器viewReslove解析后返回具体
的view
4,dispartcherServlet根据view来渲染视图,再将渲染结果返回给客户端。
20170717-接口幂等性
接口的幂等性在于无论接口被调用多少次,返回的值都是一样的。
幂等就是一个操作,不论执行多少次,产生的效果和返回的结果都是一样的。
接口幂等场景
重复下单,可以使用token去控制,
重复支付,根据生成的seq去调用支付,可以防止重复支付,如果是因为第三方平台没有及时返回支付成功状态,可以使用对账
重复调用推送接口,比如消息推送接口,如果别人多次调用可能导致用户收到重复的内容,为了防止运营的手误重复点击,对
推送内容增加判断,对推送内容进行md5加密 ,如果推送内容md5一样就直接返回推送成功,保证系统只处理一次推送请求。
20170718-线程池大小如何设置
如果是CPU密集型应用,则线程池大小设置为N+1
如果是IO密集型应用,则线程池大小设置为2N+1
20170731-mysql删除
delete语句删除的时候 表名称不能加别名例如:
DELETE from tb_media_settlement a where a.article_id in(
select t.id from tb_article t where t.custom_id=47 and t.media_id is null
)
只能用
DELETE from tb_media_settlement where article_id in(
select t.id from tb_article t where t.custom_id=47 and t.media_id is null
)
20170802-window删除大量文件和文件
删除文件和删除文件夹命令
del /f/s/q foldername > nul
rmdir /s/q foldername
20170829-findbugs插件提示的优化代码
1、Map迭代的时候,最好用 map.entrySet的形式
Map.Entry<Integer, CategoryVO> entry : map.entrySet()
2、用到equals的时候需要留个心眼,如果其他组提供的XXDTO需要比较的这个字段是Integer类型
,而你定义临时变量类型是String类型,这时候需要把Integer类型的变量转换成String类型再比较
if((shop.getShopId() + "").equals(shopId))
或者
Integer i=1;
i.equals("1") 肯定是false,因为Integer重写了equals方法。
Integer a=1;
int b=1;
Integer和int比都会自动拆箱
20170918-Comparable与Comparator
平常用到一些map的排序,可能需要重写他的排序规则。
Comparable:内比较器,一些类只要实现了这个接口,就可以自己和自己比较。
Comparator:外比较器,比如某些类没有实现Comparable接口,只能使用类似这样的写法
Map<Date, EduGoodHourStockDTO> map = new TreeMap<Date, EduGoodHourStockDTO>(new Comparator<Date>() {
@Override
public int compare(Date o1, Date o2) {
return 0;
}
});
public static class TreeValue implements Comparable<TreeValue> {
int score;
public TreeValue(int score) {
this.score = score;
}
//如果保持这个顺序就返回-1,交换顺序就返回1,什么都不做就返回0
public int compareTo(TreeValue o) {
//从小到大
if (this.score>o.score )
return 1;
//当前值小于被比较的值 返回-1 从小到大
else if (this.score <o.score )
return -1;
else
return 0;
}
}
或者
Collections.sort(configLoaders, OrderComparator.INSTANCE);
public class OrderComparator implements Comparator<Object> {
public static final Comparator<Object> INSTANCE = new OrderComparator();
public OrderComparator() {
}
public static Comparator<Object> getInstance() {
return INSTANCE;
}
//lhs first object to be compared ,rhs second
public int compare(Object lhs, Object rhs) {
Order lhsOrder = (Order)lhs.getClass().getAnnotation(Order.class);
Order rhsOrder = (Order)rhs.getClass().getAnnotation(Order.class);
if (lhsOrder == null && rhsOrder == null) {
return 0;
} else if (rhsOrder == null) {
return 1;
} else {
return lhsOrder == null ? -1 : Integer.signum(lhsOrder.value() - rhsOrder.value());
}
}
}
默认是从小到大
如果保持这个顺序就返回-1,交换顺序就返回1,什么都不做就返回0
20170924-static修饰符
static修饰的对象或者变量都是全局共享的,一个类中,一个static变量只会有一个内存空间,虽然有多个类实例,
但这些类实例中的这个static变量会共享同一个内存空间。
static的变量是在类装载的时候就会被初始化,即,只要类被装载,不管是否使用了static变量,都会被初始化
20170925-Exception与RuntimeException
自定义异常继承了Exception就必须要强制检查
自定义异常继承了RuntimeException 不需要强制检查
20170928-公司同事guva分享记录
字符串截取: ",a,,b,c" 按照逗号截取
20171012-包装类比较
Integer包装类比较的时候最好用equals去比较,因为equals会将Integer转换成int类型去比较
20171018-String.replace注意
String 自带有好几种替换方式,
例如 replace(),replaceFirst(),replaceAll()
如果我们使用replace() 参数就是CharSequence
如果使用replaceFirst(),replaceAll() 被比较的参数就是regex正则后的字符串.
比如"$"这个字符属于特殊字符 那么可以使用 replace("$") 和replaceFirst("\\$")
20171024-map.putIfAbsent(key,value)
map 其实有一个方法叫map.putIfAbsent(key,value),
如果已经存在了,就不会再添加了,返回旧的value
如果不存在,就返回空的value类型(null或者"")
map.put(key,value) 返回的是oldValue;
20171106- URLEncoder.encode()与decode()
url encode与decode 有两大功能
1、解决中文在get提交的时候乱码问题,只要encode和decode的字符集一样,肯定不会出现乱码情况,而且某些特殊
字符也不允许出现在url里面
2、解决url里面带url的情况
比如: http://www.baidu.com?param1=aa&redirectUrl=http://www.dianping.com?p1=bb&&p2=cc&¶m2=dd
我们想要的是:redirectUrl=http://www.dianping.com?p1=bb&&p2=cc
但是如果不encode最终传输的url解析到的就是redirectUrl=http://www.dianping.com?p1=bb
p2=cc这个参数就会被丢失。
20171122- utf-8与gbk
一个中文在uft-8下面占用三个字节,在gbk下面占用2个字节
20180119-maven依赖原则
1.间接依赖路径最短优先
一个项目test依赖了a和b两个jar包。其中a-b-c1.0 , d-e-f-c1.1 。由于c1.0路径最短,所以项目test最后使用的是c1.0。
2.pom文件中申明顺序优先
有人就问了如果 a-b-c1.0 , d-e-c1.1 这样路径都一样怎么办?其实maven的作者也没那么傻,会以在pom文件中申明的顺序那选,
如果pom文件中先申明了d再申明了a,test项目最后依赖的会是c1.1
所以maven依赖原则总结起来就两条:路径最短,申明顺序其次。
20180122-简单的linux脚本
for i in {1..27}
do
curl -o $i.txt http://www.dianping.com/sitemap/education/mt/shop/$i.txt
done
20180208-mysql utf8_unicode_ci、utf8_general_ci的区别
i是 case insensitive, 即 "大小写不敏感", a 和 A 会在字符判断中会被当做一样的;
bin 是二进制, a 和 A 会别区别对待.
例如你运行:
SELECT * FROM table WHERE txt = 'a'
那么在utf8_bin中你就找不到 txt = 'A' 的那一行, 而 utf8_general_ci 则可以.
utf8_general_ci 不区分大小写,这个你在注册用户名和邮箱的时候就要使用。
utf8_general_cs 区分大小写,如果用户名和邮箱用这个 就会照成不良后果
utf8_bin:字符串每个字符串用二进制数据编译存储。 区分大小写,而且可以存二进制的内容
20180306- mysql unique与primary
数据基础知识了,primary key = unique + not null
unique修饰的key 可以为空
一个表只能有一个主键,但是可以有好多个UNIQUE
insert into values与value
values 插入单条记录快
value 插入多条记录快
20180307- mysql longText与text类型
longText:4294967295/3=1431655765个汉字,14亿,存储空间占用:4294967295/1024/1024/1024=4G的数据;
text:65535/3=21845个汉字,约20000,存储空间占用:65535/1024=64K的数据;
20180308- less倒序
less xx.log, shift+g移动到最后一行,ctrl+b往前
20180313-字符串以逗号隔开
StringUtils.join(list,",")
20180402-mysql bit
mysql长度int(m) M指示最大显示宽度。最大有效显示宽度是255。显示宽度与存储大小或类型包含的值的范围无关;
我们建立这个长度是为了告诉MYSQL数据库我们这个字段的存储的数据的宽度为5位数, 当然如果你不是5位数(只要在该类型的存储范围之内)MYSQL也能正常存储,
MySQL5.0以前,BIT只是TINYINT的同义词而已。但是在MySQL5.0以及之后的版本,BIT是一个完全不同的数据类型
tinyint 1字节,smallint 2字节,mediumint 默认3字节,int 4字节,bigint 8字节
BIT(M)类型允许存储M位值,M为位数,默认为4,如果M位1,那就是0或者1,可以用来表示是否删除字段
TINYINT 一个字节,支持 -128到127(SIGNED),0到255(UNSIGNED)
bigint 8个字节带符号的 9223372036854774807,不带符号的18446744073709551615
BOOL——同TINYINT(1)
DATETIME 8个字节 固定格式格式:'YYYY-MM-DD HH:MM:SS' 范围为1000-01-01 00:00:00 ~ 9999-12-31 23:59:59
TIMESTAMP 4个字节 范围为1970-01-01 08:00:01到2038-01-19 ,timestamp会跟随设置的时区变化而变化,而datetime保存的是绝对值不会变化。
VARCHAR(M) M是字符数,在utf-8模式下 一个中文等于一个3字节
TINYBLOB, TINYTEXT L+1 字节, 在此L< 2 ^ 8
BLOB, TEXT L+2 字节, 在此L< 2 ^ 16
20180412- 不停机数据迁移与分表
随着业务递增,单表查询效率降低,所以需要进行分表操作,同时因为这个表的特殊性,需要将表从A库迁移到B库之后再分表。
一、数据迁移
1、上线双写代码,所有写操作都会写A库同时,也会写一份到B库,但是查只查A库
2、进行数据迁移,用脚本或者job将A库的全量数据,同步到B库
3、A与B库数据一致性比对job。
4、上线取消写A库代码的数据源,同时改成查B库,下线A库,
二、分表
1、新增分表键字段,根据分表键取模%128 新建多128分表
2、上线分表代码,表新的写操作都会写入不同的表,读只读主表。
3、job将主表的数据全量同步到给个分表,可以同步java代码,也可以通过读取全量的binlog日志
4、上线分表代码,根据分表键读取不同的表。
20180417- @Resource与@Autowired等常用注解
@Resource、@PostConstruct以及@PreDestroy 是JSR-250规范定义的注解
@Resource与@Autowried的区别在于 @Resource是基于bean的ame进行注入的,而@Autowried是基于bean类型注入的
@Resource有两个参数name和type,默认都不填则按照bean的name进行注入的。
使用场景,比如一个接口多个实现:
可以使用 @Autowired+@Qualifie 或者@Resource+不同的bean的name
@Autowired默认是按照类型来找的,如果一个接口两个实现,因为类型一致,Autowired的兜底方案是根据@Autowired变量的byname去找
@Service用于标注业务层组件
@Controller用于标注控制层组件(如struts中的action)
@Repository用于标注数据访问组件,即DAO组件F
@Component泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注。
20180421- Java泛型中E、T、K、V等的含义
E表示element 数组、集合之类
T表示 Type(Java 类)
K - Key(键)
V - Value(值)
N - Number(数值类型)
? - 表示不确定的java类型
S、U、V - 2nd、3rd、4th types
20180502- BigDecimal注意事项
new BigDecimal(0.03) 会出现丢失精度,最好使用 new BigDecimal("")
BigDecimal的比较要用compareTo ,不能用equal
BigDecimal的除法要养成习惯去设置精度,以免出现无限循环小数而抛异常。
20180509- jvm异常退出hook线程
jvm强制退出的时候 等待ShutdownHook程序执行完全,
但如过JVM由于某些内部错误而崩溃,或(Unix / Linux中的kill -9)或TerminateProcess(Windows)),
那么应用程序需要立即终止而不会甚至等待任何清理活动
关闭钩子本质上是一个线程(也称为Hook线程),对于一个JVM中注册的多个关闭钩子它们将会并发执行,
所以JVM并不保证它们的执行顺序;由于是并发执行的,那么很可能因为代码不当导致出现竞态条件或死锁等问题,
为了避免该问题,强烈建议在一个钩子中执行一系列操作
Runtime.getRuntime().addShutdownHook()
20180523- java位移运算与与运算
首先位移运算肯定是高效的,jdk源码有大量使用
(1)机器都是使用补码,运算也是使用补码运算。
(2)正数的原码补码反码都一样。
(2)补码与原码相互转换,其运算过程是相同。
带符号左位移运算符<< ,数值的补码全部往左移动X位: a<<1 等于a*2 ,左移n位就相当于乘以2的n次方
例如1<<1 等于0001向左边位移一位,00010
带符号右位移运算符>> a>>1 等于a/2 ,右移n位就相当于除以2的n次方
&与运算,就是按位与运算,两个1才是1,否则都是0
例如2&1 等于0010和0001 与运算,结果就是0000。
一般常用的就是某个数a&1,那么结果要么是0要么是1。
20180524- spring事物@Transactional
spring的事物默认回滚非运行时异常RunTimeException,如果指定了rollbackFor的异常类型,例如Exception.class 那就需要
在try catch 之后再 throw exception,才会回滚。
注意1:
如果在controller层调用service层(service层没有加类级别的@transtaionl注解)的A方法(没有加@transtaionl),
A方法里面再调用B方法(加了@Transactional propagation = Propagation.REQUIRES_NEW))
这时候B方法的事物也不会起效的。)
注意2:spring 事务REQUIRES_NEW 不起作用
如果在同一个类里面,A方法(有事务)调用B方法(要独立新事务) 这时候B的事务REQUIRES_NEW是不会新建的。
解决方法:需要将两个方法分别写在不同的类里。或者 方法写在同一个类里,但调用B方法的时候
,将service自己注入自己,用这个注入对象来调用B方法
注意3:spring对于Propagation.REQUIRES_NEW的回滚策略
不同的Service调用方法时:
如果被调用方法是Propagation.REQUIRES_NEW,被catch后不抛出,事务可以正常提交;
如果被调用方法是Propagation.REQUIRED,被catch后不抛出,后面的代码虽然可以执行下去,但最终还是会分出rollback-only异常;
同一个Service中调用方法时:
不论被调用方法注解是Propagation.REQUIRES_NEW 还是 Propagation.REQUIRED,其结果都是一样的,就是都被忽略掉了,等于没写。
当其抛出异常时,只需catch住不抛出,事务就可以正常提交。
注意4:有事物的A方法调用没有事物的B方法(假设A、B不在同一个类),因为事物的传播特性,B方法的执行也是在A方法的事物里面的。
在一个Service内部,事务方法之间的嵌套调用,普通方法和事务方法之间的嵌套调用,都不会开启新的事务.
是因为spring采用动态代理机制来实现事务控制,而动态代理最终都是要调用原始对象的,而原始对象在去调用方法时,是不会再触发代理了!
如果最外层方法有事物,那么其他的方法都是用同一个事物,如果最外层方法没有事物,那就以非事物行为调用。
注意5:使用事物的时候最好设置事物的超时时间,比如批量插入和更新,或者一些rpc服务调用,都会长时间占用连接,导致数据库连接不够用。
20180524- spring @Transactional注解被加载初始化顺序
了解事物初始化顺序需要先了解一些其他东西。
- InfrastructureAdvisorAutoProxyCreator
这个类的父类AbstractAutoProxyCreator实现了BeanPostProcessor而BeanPostProces的接口postProcessAfterInstantiation()
会在所有bean你都实例化完成后被调用到。
AbstractAutoProxyCreator的父类是AbstractAdvisorAutoProxyCreator
它会自动获取spring容器中注册的所有的Advisor类(除了子类中isEligibleAdvisorBean()
方法指定的不满足条件的Advisor除外。),然后自动给spring容器中满足Advisor中pointCut创建代理。
1
注册InfrastructureAdvisorAutoProxyCreator和advisor BeanFactoryTransactionAttributeSourceAdvisor
2
spring Bean实例化后调用BeanPostProcessor的回调函数postProcessAfterInitialization
然后根据BeanFactoryTransactionAttributeSourceAdvisor 对满足条件的bean进行增强代理
3
若目标类的方法上存在@Transactional事务注解,那么就是满足条件的,会用TransactionAttributeSourcePointcut对类生成advisorProxyFactory生成代理
AbstractAutoProxyCreator 创建增强类相关代码
protected Object createProxy(
Class<?> beanClass, String beanName, Object[] specificInterceptors, TargetSource targetSource) {
if (this.beanFactory instanceof ConfigurableListableBeanFactory) {
AutoProxyUtils.exposeTargetClass((ConfigurableListableBeanFactory) this.beanFactory, beanName, beanClass);
}
ProxyFactory proxyFactory = new ProxyFactory();
proxyFactory.copyFrom(this);
if (!proxyFactory.isProxyTargetClass()) {
if (shouldProxyTargetClass(beanClass, beanName)) {
proxyFactory.setProxyTargetClass(true);
}
else {
evaluateProxyInterfaces(beanClass, proxyFactory);
}
}
Advisor[] advisors = buildAdvisors(beanName, specificInterceptors);
for (Advisor advisor : advisors) {
proxyFactory.addAdvisor(advisor);
}
proxyFactory.setTargetSource(targetSource);
customizeProxyFactory(proxyFactory);
proxyFactory.setFrozen(this.freezeProxy);
if (advisorsPreFiltered()) {
proxyFactory.setPreFiltered(true);
}
return proxyFactory.getProxy(getProxyClassLoader());
}
4
根据目标类和BeanFactoryTransactionAttributeSourceAdvisor(回调链中的一个)生成代理代理类被调用,触发回调函数
5
最后调用BeanFactoryTransactionAttributeSourceAdvisor中advice(TransactionInterceptor)的回调函数
TransactionInterceptor完成事务的管理
BeanFactoryTransactionAttributeSourceAdvisor advisor = new BeanFactoryTransactionAttributeSourceAdvisor();
advisor.setTransactionAttributeSource(transactionAttributeSource());
advisor.setAdvice(transactionInterceptor());
advisor.setOrder(this.enableTx.<Integer>getNumber("order"));
BeanFactoryTransactionAttributeSourceAdvisor里面的advice是TransactionInterceptor
6
所有@Transation事物的拦截都是调用TransactionInterceptor的 invoke()方法
20180525-git回滚代码
1、删除远程分支再提交
第一种方法不建议,比较麻烦。
1.1 先两步保证当前工作区是干净的,并且和远程分支代码一致
git pull origin master
1.2 创建备份当前分支
git branch olderMaster
git branch revertBranch
git chekout revertBranch
1.3 reset到待提交的分支
git log 找到待会滚的提交versio
git reset --hard resetVersionHash
1.4 删除当前分支的远程分支
git push orgin:master
如果删除失败,可能当前分支就一个,需要切换到其他分支去删除
删除本地分支
git branch -D master
1.5 当前分支提交到远端
当前分支名称修改为master
git branch -m master
git push origin master
2、强制push远程分支
1.reset到待提交的分支
2、把当前分支强制提交到远程
git push -f origin currentBranch
3、从回滚位置生成新的commit hash
1、git revert 到等待回滚的versio
2、git push origin
20180529- Arrays.asList(xx)
对于Arrays.asList()生成的list,如果我们在对其get再add操作会报错java.lang.UnsupportedOperationException
因为Arrays.asList()生成的是匿名类的Arrays.ArrayList而不是java.util.ArrayList
20180628- 避免mybatis SUM求和返回null
select COALESCE(SUM(ScanCount),0) from table
20180712- mysql对于null的处理
select 1 is null, 1 is not null, 1 <=> null ,null <=>null, 1 = null, 1 != null, 1 <> null from dual
任何值与null做=或!=或<>运算,所得结果均为null,在判断中即为false。
例如 select * from db where a!='ddd' ,如果db表里面有三条数据,a字段值都为null,那么查询结果返回是0行数据
20180815-mybatis批量插入时候自增主键
https://github.com/mybatis/mybatis-3/pull/324
注意点,dao去掉@param mapper里面 parameterType="java.util.List"
<insert id="saveList" useGeneratedKeys="true" keyProperty="vcourseId" parameterType="java.util.List">
insert into EduVCourse (VCourseName, VCourseDesc,IsDeleted, AddTime) values
<foreach collection="list" item="item" separator=",">
(#{item.vcourseName},#{item.vcourseDesc},0, now() )
</foreach>
</insert>
20180905-mysql支持emoj
有两种方式:升级MySQL到5.6或更高版本,并且将表字符集切换至utf8mb4。
第二种方法就是在把内容存入到数据库之前做一次过滤,将Emoji字符替换成一段特殊的文字编码,
然后再存入数据库中。之后从数据库获取或者前端展示时再将这段特殊文字编码转换成Emoji显示。
20180906-一致性hash
当我们设计分布式存储时候,肯定会遇到数据平均存储的问题,一般采用Hash算法。
假设初始节点数为 N,则传统的对 N 取模的映射方式存在一个问题,当节点增删,即 N 值变化时,
整个哈希表(Hash Table)需要重新映射,这便意味着大部分数据需要在节点之间移动。
比如有三台机器,假设每条待存储的数据都有一个唯一key,那么我们可以根据机器数量取模 shardNO=key%number得到hash值
那么shardNO无非就是0,1,2。
如果从三台扩成6台,数据迁移是这样的:
原来机器0的数据迁移到(0,3),机器1的数据迁移到(1,4),机器2的数据迁移到(2,6)
如果从三台库扩容4台,数据迁移是这样的:
0==>(1,2),1==>(0,3),2==>(0,1),数据需要迁移6次
如果从三台库到5台,数据迁移是这样的
0==>(1,2,4),1==>(0,2,4),2==>(0,3,1),数据需要迁移9次
考虑到性能,最好是是指数级别扩容需要迁移数据最少。
但是这种方式有两个缺点,一个是指数级别扩容,当指数级别比较大就是浪费,一个是需要数据扩容,数据迁移也是成本。
一致性Hash算法
参考:https://my.oschina.net/lionets/blog/288066
当增删节点时,只影响到与变动节点相邻的一个或两个节点,散列表的其他部分与原来保持一致。
某种程度上可以将其理解为:一致性哈希算法的哈希函数与节点数 N 无关。
一致性hash算法通过一个叫作一致性hash环的数据结构实现。这个环的起点是0,终点是2^32 - 1,并且起点与终点连接,
环的中间的整数按逆时针分布,故这个环的整数分布范围是[0, 2^32-1]。
下一步将各个服务器使用Hash进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,
这样每台机器就能确定其在哈希环上的位置,假设将四台服务器使用ip地址哈希后在环空间的位置如下
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,
从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。

例如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:

根据一致性哈希算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
下面分析一致性哈希算法的容错性和可扩展性。现假设Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,
只有C对象被重定位到Node D。一般的,在一致性哈希算法中,如果一台服务器不可用,
则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
如果这时候新增一台服务器Node X

此时对象Object A、B、D不受影响,只有对象C需要重定位到新的Node X 。一般的,在一致性哈希算法中,
如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,
其它数据也不会受到影响。综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
一致性Hash算法优化
致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如系统中只有两台服务

此时必然造成大量数据集中到Node A上,而只有极少量会定位到Node B上
为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,
称为虚拟节点。
具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,可以为每台服务器计算三个虚拟节点,
于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点

同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。这样就解决了服务节点少时数据倾斜的问题
20180911-集合求并结果集
例如有两个集合A(1,2,3),B集合(3,4,5),A和B的并集是3,常用方法是就是循环A,然后再去看B里面有没有,其实jdk里面提供了求并集的方法
list.retainAll(list2)
20180920-Java位运算的使用场景
1、乘法 a * (2^n) 等价于 a << n
3*2=3<<1
3*4=3<<2
2、除法 a / (2^n) 等价于 a>> n
8/2=8>>1
8/4=8>>2
3、取模运算,采用位运算实现 a % (2^n) 等价于 a & (2^n - 1)
9%4=9&3
20180921-网络ping命令
traceroute命令用于追踪数据包在网络上的传输时的全部路径,它默认发送的数据包大小是40字节
ping命令用来测试主机之间网络的连通性
20180927-&&与||
最近发现脑子不够用
a()&&b()&&c() 表示a()方法为true,才会执行b(),如果a()为false,就不会执行后面的
a()||b()||() 表示a()方法为true,就不会执行后面的,如果为false才会执行后面的
20180928 BeanUtils.copyProperties浅拷贝
spring提供的bean对象拷贝是浅拷贝,如果对象里面有引用或者集合对象是不会被拷贝的。
可以自己重新clone()或者利用jdk的ByteArrayOutputStream和ByteArrayInputStream 序列化对象
20181018 hash冲突解决方法
1、链表方法
创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可,例如HashMap
2、线性探测
根据key的得到hashValue,若不冲突,则直接填入数组,若冲突,则使 hashValue++ ,也就是往后找,
直到找到第一个 data[hashValue] 为空的情况,则填入。若到了尾部可循环到前面
ThreadLocalMap就是这样实现的
private static void add(String str,String value) {
int ix= str.hashCode()&size;
System.out.println(str+":hashcode:"+ix);
//如果冲突就获取下一个array[]的值
for (Entry st=array[ix];st!=null;st=array[ix=ix+1]) {
if(st.key==str){
st.value=value;
return;
}
}
array[ix]=new Entry(null,str,value);
}
20181026-spring自定义添加bean
ConfigurableWebApplicationContext cwac = (ConfigurableWebApplicationContext) applicationContext;
DefaultListableBeanFactory beanFactory = (DefaultListableBeanFactory) cwac.getBeanFactory();
// 自己注册bean
BeanDefinitionBuilder beanDefinitionBuilder = BeanDefinitionBuilder
.genericBeanDefinition(CustomBean.class.getName());
//设置依赖bean 这个bean前提是已经被spring代理了
beanDefinitionBuilder.addPropertyReference("refrenceBean","refrenceBean");
beanFactory.registerBeanDefinition("customBean", beanDefinitionBuilder.getBeanDefinition());
// 去除beani
// beanFactory.removeBeanDefinition("customBean");
2019
20190122-数据统计
最近接手一个作业系统,里面表结构设计有很多冗余字段,冗余但统计字段无法保证数据的准确性,所以设计的时候就不改将统计的信息
放到表的字段里面,统计的信息最好是通过base表实时查,这样牺牲性能保证一致性,当然企业级开发不需要考虑这么全,数据量大了需要
专门走bi进行查询统计,让业务部门来做统计的事情本来就很重。
20190325-linux 脚本
临时变量
单引号:在单引号中,变量不能被解析;
双引号:在双引号中变量可以被解析
反引号:反引号的作用是将反引号括起来的命令(括起来的内容会被当成命令执行),然后将结果赋值给一个变量。
#!/bin/bash
tempPath=`pwd`
gradle clean build -x test -Dprofile=dev
echo -e '密码'
scp -P 5044 "${tempPath}"/homework-api/build/libs/homework-api.jar dev@xxx:/home/dev/download
20190506-iaas pass sass
iass :infrastructure as a service
是云服务的最底层,主要提供一些基础资源
pass: platform as a service
提供软件部署平台(runtime),抽象掉了硬件和操作系统细节,可以无缝地扩展(scaling)。开发者只需要关注自己的业务逻辑,不需要关注底层
sass: software as a service
是软件的开发、管理、部署都交给第三方,不需要关心技术问题,可以拿来即用
20190507-线程自动扩展策略
1、根据队列的长度进行扩展,如果核心线程数一开始不等于最大线程数,可以自动扩展核心线程数到最大线程数。
2、根据队列使用率进行扩展
3、动态修改线程数核心参数和最大线程数
20190508-单点登陆
sso分为认证和登陆两个过程
认证(用户名,密码)得到一个authorizationCode
登录(accessToken,authorizationCode) 得到第一个登录凭据(ticket)(存在sso系统的cookie下面 应用系统也会写一份)
检查登录态(accessToken,ticket) 得到用户的用户名(loginName)
登出(accessToken,ticket) 得到登出用户的用户名(loginName)
20190519-延迟队列
定时器轮询遍历数据库记录
优点:不依赖其他技术,开发简单
缺点:当某一刻需要执行的数据量比较大,会影响性能,而且频繁轮训数据库也是不必要的开销
JDK的DelayQueue
优点:进程内的
缺点:单机的、每次消费的时候还需要单独启线程
JDK ScheduledExecutorService
时间轮(netty)
利用quartz等定时任务
Redis的ZSet实现
https://tech.youzan.com/queuing_delay/
rabbitMq实现延时队列
解决延迟队列有很多种方法。选择哪个解决方案也需要根据不同的数据量、实时性要求、
已有架构和组件等因素进行判断和取舍。对于比较简单的系统,可以使用数据库轮训的方式。
数据量稍大,实时性稍高一点的系统可以使用JDK延迟队列(也许需要解决程序挂了,内存中未处理任务丢失的情况)。
如果需要分布式横向扩展的话推荐使用Redis的方案。但是对于系统中已有RabbitMQ,那RabbitMQ会是一个更好的方案。
参考:https://www.jianshu.com/p/a8c1458998aa
20190902-公众号
ulimit -u 可以查看和设置系统的最大并发进程数
20190904-Javassist、ASM
ASM 是一个 Java 字节码操控框架。它能够以二进制形式修改已有类或者动态生成类。
ASM 可以直接产生二进制 class 文件,也可以在类被加载入 Java 虚拟机之前动态改变类行为。
ASM 从类文件中读入信息后,能够改变类行为,分析类信息,甚至能够根据用户要求生成新类
Javassist是一个开源的分析、编辑和创建Java字节码的类库。
javassist是jboss的一个子项目,其主要的优点,在于简单,而且快速。
直接使用java编码的形式,而不需要了解虚拟机指令,就能动态改变类的结构,或者动态生成类
20190905-高并发减少锁竞争方式
1、减少锁的持有时间,换句话说就是不需要锁的操作从同步代码块移走
public synchronized void lockObject(String name) {
for (int i = 0; i < 10; i++) log.info("name:" + name);
log.info("synchronized void lockObject:" + name);
for (int i = 0; i < 10; i++) log.info("out name:" + name);
}
优化为:
public void lockObject(String name) {
for (int i = 0; i < 10; i++) log.info("name:" + name);
synchronized (this) {
log.info("synchronized void lockObject:" + name);
for (int i = 0; i < 10; i++) log.info("out name:" + name);
}
}
2、减少锁的粒度,比如原本是基于类的锁,可以扩大为基于多个对象的锁,
举个例子:
private final ArrayList fruits = new ArrayList();
public synchronized void addFruit(int index, String fruit) {
fruits.add(index, fruit);
}
优化
public void addFruit(int index, String fruit) {
synchronized(fruits) fruits.add(index, fruit);
}
3、读写锁分离
20190917-模版word 生成方案
模版word生成可以用xml模版和mht模版,如果word里面有富文本那就必须要用mht模版,
生成模版的时候不能用wps,得用原生的word,样式的化需要注意将”sytle=” “style=3D”替换下
还有就是”=”是特殊字符,如果要展示就需要替换成”==””
mht图片格式需要注意以下几个细节
1、
<#list imgPartList as img>
——=_NextPart_01D56BB9.7917EAB0
Content-Location: file:///C:/D1A954B2/word2.fld/${img.resId}
Content-Transfer-Encoding: base64
Content-Type: ${img.type}
${img.binary}
</#list>
</#if>
3、
20190923-jmh BenchMark压测
方法级别的压测可以使用jmh,jmh提供预热功能,还有各个纬度的压测指标
再也不用自己手写循环代码
20190926-一些不常用当方法
//如果map里面存在这个值 就不覆盖,直接返回以前当值。
map.putIfAbsent(key, value)
//blist去除alist 里面存在的元素
List<QuestionOptionResult.Node> hiddenQuestionTypeList
hiddenQuestionTypeList.forEach(hiddenQuestionType -> {
questionTypeNodeList.removeIf(type -> type.getCode().equals(hiddenQuestionType.getCode()));
});
20190929- mac 端口占用
sudo lsof -i :9000
mac 下载东西
curl -o apache-zookeeper-3.5.6.tar.gz https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.5.6/apache-zookeeper-3.5.6.tar.gz
20191104-static代码块方法没有执行
static块是在类初始化时候被调用的,不是类加载时候调用的
如果一个静态变量(基本类型或者字符串)被final修饰,且不是在static块里面对变量赋值,那么变量在编译期间就把结果放入了常量池
所以在类名调用的变量时候,是不会初始化类的
//不会调用static块方法
public final static String FINAL_STATIC_NAME = "father";
static {
System.out.println("这是【父类】静态代码块");
}
//虽然被final修饰,但是在static里面赋值 是会调用static对
public final static String FINAL_STATIC_NAME ;
static {
FINAL_STATIC_NAME="father";
System.out.println("这是【父类】静态代码块");
}
20191209-Java程序运行过程
看到专栏里面有个总结挺有意思的记录下
一句话概述了方法区,堆、栈、计数器的各自特性
方法区主要存放从磁盘加载进来的类字节码,而在程序运行过程中创建的类实例则存放在堆里。
程序运行的时候,实际上是以线程为单位运行的,当 JVM 进入启动类的 main 方法的时候,就会为应用程序创建一个主线程
,main 方法里的代码就会被这个主线程执行,每个线程有自己的 Java 栈,栈里存放着方法运行期的局部变量。
而当前线程执行到哪一行字节码指令,这个信息则被存放在程序计数寄存器
一个典型的 Java 程序运行过程
通过 Java 命令启动 JVM,JVM 的类加载器根据 Java 命令的参数到指定的路径加载.class 类文件,
类文件被加载到内存后,存放在专门的方法区。然后 JVM 创建一个主线程执行这个类文件的 main 方法,
mian 方法的输入参数和方法内定义的变量被压入 Java 栈。如果在方法内创建了一个对象实例,
这个对象实例信息将会被存放到堆里,而对象实例的引用,也就是对象实例在堆中的地址信息则会被记录在栈里。
堆中记录的对象实例信息主要是成员变量信息,因为类方法内的可执行代码存放在方法区,而方法内的局部变量存放在线程的栈里。
20191210-linux软连接
ln -s /usr/local/Cellar/python/3.7.3/Frameworks/Python.framework/Versions/3.7/bin/* /usr/local/bin/
20191211-引用传值
引用”也就是指向真实内容的地址值,在方法调用时,实参的地址通过方法调用被传递给相应的形参,
在方法体内,形参和实参指向同一个内存地址,对形参的操作会影响的真实内容
引用传递的是对象的副本
如果对象被重新创建或赋值为null,即new会重新指向其他对象,不影响其原对象的值
@Setter
@Getter
private Parent p;
public static void main(String[] args) {
Parent parent=new Parent();
Test test=new Test();
test.setP(parent);
parent=null;//不指向任何对象
//但是test 还是持有test对象的引用
System.out.println(parent+":" + test.getP());
}
null:com.ggj.java.reflect.Parent@7291c18f
20191214-for update导致死锁问题
使用for update时候 where后面条件一定要用带索引的键,才可以锁行,不然就会锁住整个表
for update 在使用索引的键到情况下,如果查询到记录 就加row 锁 如果查询不到就不加锁
mysql在RR事物隔离级别时候 如果for update查询不到记录 会加上gap锁
错误日志:
###EXCEPTION:org.springframework.dao.DeadlockLoserDataAccessException:
### Error updating database. Cause: com.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException:
Deadlock found when trying to get lock; try restarting transaction
伪sql:
selet * from teacher_profile where teacher_id =#{teacherId} and type=#{type} for update
//......
insert ***
假设表里面不存在记录为 a,b
| session1 | session2 |
|---|---|
| begin | |
| begin | |
| select* from table where name=a for update | |
| select* from table where name=b for update | |
| insert into table name values a | |
| 锁等待中 | insert into table name values b |
| 锁等待解除 | 死锁 session2的事物回滚 |
两个session同时通过select for update 如果没有查询到记录可能获取到相同到gap锁,
这时候进行插入的时候,session 1 插入意向锁后等待session2释放gap锁
session2也插入意向锁 等待session1到释放gap锁
这时候就形成死锁,mysql检测到后,innodb会强制关闭其中一个事物
20191217-项目工程骨架
xxx-api: 对外提供http服务,也就是常说的controller层
xxx-task: 定时任务(当任务数量比较多 需要抽出去单独服务)
xxx-core/xxx-service: 业务逻辑层
xxx-repository: 数据层 db/redis/等
xxx-integration:对接第三方接入层(http/rpc)
xxx-contract: 对外提供rpc接口和dto层
xxx-domain: 数据库层Javabean
xxx-common: 公共服务层(可以抽出去 公共维护)
20191226-springcloud 链路追踪
其实就是用zipkin收集日志信息
利用Spring Cloud Sleuth可以快速搭建一个链路追踪框架
2020
20200101-队列和栈区别
队列 :先进先出FIFO(First Input First Output)
新元素(等待进入队列的元素)总是被插入到链表的尾部,
而读取的时候总是从链表的头部开始读取。
栈 :先进后出 FILO(First In Last Out)
入栈:它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素
出栈:它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素
栈就是一个桶,后放进去的先拿出来,它下面本来有的东西要等它出来之后才能出来。(后进先出)
队列只能在队头做删除操作,在队尾做插入操作.而栈只能在栈顶做插入和删除操作。(先进先出)
20200116- lock使用锁没有释放
用jmh写rpc压测的时候,进程一直执行没有结束
看了下代码里面有类似这样的结构
lock.lock();
//double check
if (clientConnectMap.containsKey(className)) {
return clientConnectMap.get(className).getChannelFuture();
}
try {
catch (Exception e) {
log.error("init netty client error", e);
throw e;
} finally {
lock.unlock();
}
获取缓存那步提前return了导致锁没有关
202001167-uml规则
继承。带三角箭头的实线,箭头指向父类
实现。带三角箭头的虚线,箭头指向接口
关联成员变量。带普通箭头的实心线,指向被拥有者
依赖。带箭头的虚线,指向被使用者
20200224- object=null
一个对象可以有多个引用,感觉这种基础问题还会搞忘记有点傻了。
Object a = new Object();
Object b = a;
Object c = b;
只创建了一个对象,而它的引用有三个
当 a=null的时候,只是a指向堆内存堆引用没了,但bc 还有引用
20200313-队列一些不常用等方法
poll 移除,并返问队列头部的元素
peek 返回队列头部的元素
push 添加数据
blockquene:
put 与 take 会block
offer和poll 不会block
20200405-java日志框架历史
参考:https://zhuanlan.zhihu.com/p/24272450
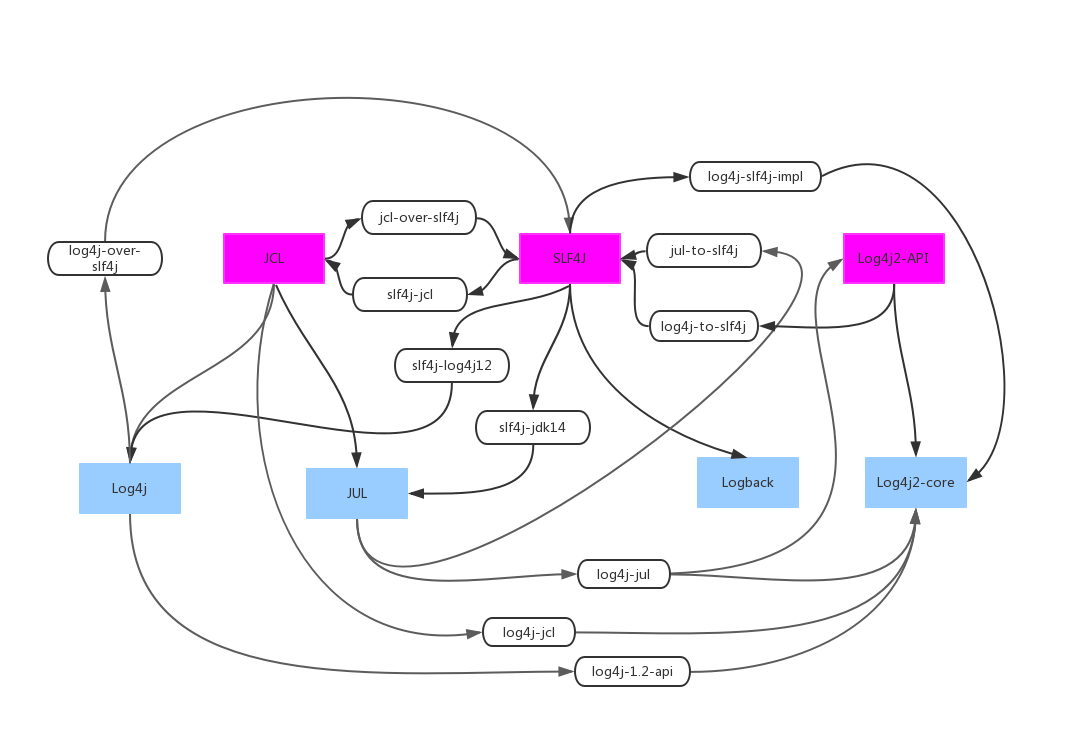
一句话总结:
JUL(Java Util Log), JCL(Commons Logging), Log4j, SLF4J, Logback,Log4j2
JCL与SLF4J是提供logapi,JUL与Log4j、Logback、Log4j2都可以通过对应都jar包实现互转
Java Util Log
jdk自带的log,使用不是特别广泛
Log4j 1.x
性能比较差
Commons Logging
JCL 是一个Log Facade,只提供 Log API,不提供实现。
早期jcl就相当于sl4j,有 Adapter来使用 Log4j或者JUL作为Log Implementation
slf4j
SLF4J(The Simple Logging Facade for Java)和 Logback 也是Gülcü 创立的项目,
其创立主要是为了提供更高性能的实现。其中,SLF4j 是类似于JCL 的Log Facade,
Logback 是类似于Log4j 的 Log Implementation
为什么有了JCL还要重复造个轮子sl4j了
因为sl4jz作者觉得JCL的API设计得不好,容易让使用者写出性能有问题的代码
例如:logger.debug("start process request, url:" + url);
一般生产环境 log 级别都会设到 info 或者以上,那这条 log 是不会被输出的。
然而不管会不会输出,这其中都会做一个字符串连接操作,然后生产一个新的字符串。
如果这条语句在循环或者被调用很多次的函数中,就会多做很多无用的字符串连接,影响性能
所以 JCL 的最佳实践推荐这么写:
if (logger.isDebugEnabled()) {
logger.debug("start process request, url:" + url);
}
然而开发者常常忽略这个问题或是觉得麻烦而不愿意这么写。所以SLF4J提供了新的API,方便开发者使用:
logger.debug("start process request, url:{}", url);
Log4j2
Log4j2也做了Facade/Implementation分离的设计,分成了log4j-api和log4j-core
计上很大程度上模仿了 SLF4J/Logback,性能上也获得了很大的提升
log优化
具体的日志实现依赖应该设置为optional和使用runtime scope
设为optional,依赖不会传递,这样如果你是个lib项目,然后别的项目使用了你这个lib,
不会被引入不想要的Log Implementation 依赖;
Scope设置为runtime,是为了防止开发人员在项目中直接使用Log Implementation中的类,
而不适用Log Facade中的类。
避免为不会输出的log付出代价:
避免以下这种写法:
logger.debug("start process request, url: " + url);
logger.debug("receive request: {}", toJson(request));
使用:
logger.debug("start process request, url:{}", url); // SLF4J/LOG4J2
logger.debug("receive request: {}", () -> toJson(request)); // LOG4J2
logger.debug(() -> "receive request: " + toJson(request));
20200417-正则表达式
\ 转义符号
^ 匹配行首
$ 匹配行尾
{n} 匹配确定的n次
{n,} 至少匹配n次
{n,m} 最少匹配n次且最多匹配m次
* 匹配任意次 {0,}
+ 匹配前面的子表达式一次或多次(>=1次) {1,}
? 匹配零次或者1次 <=1 {0,1}
x|y 匹配x或者y
[xyz] 配所包含的任意一个字符
[^xyz] 负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”任一字符。
[a-z] 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。
(pattern) 匹配pattern并获取这一匹配
\d \\d匹配一个数字字符。等价于[0-9]
\W 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”
\w 匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用Unicode字符集
20200418-返回值多次排序
第一个参与排序的放到最后面
resultList.stream().sorted((o1, o2) -> o1.getSortClassName().compareTo(o2.getSortClassName())).
sorted((o1, o2) -> o1.getGradeNum().compareTo(o2.getGradeNum())).collect(Collectors.toList())
05-12-mysql索引失效
相关表索引(department_id、employee_id)都加过
select
*
from
teacher,
employee_department
where
teacher.employee_id = employee_department.employee_id
and employee_department.department_id in(4883111)
-- and teacher.is_delete = 0
如果加了 and teacher.is_delete = 0这行 ,expalin看执行效率时候会teacher表会ALL 全表扫描
如果不加 and teacher.is_delete = 0这行,expalin teacher表会走索引
最后定位下其实和这个and后面条件无多大关系
mysql分析时候觉得数据的比例已经超过了使用索引的比例(比如对象数据:所有数据>20%),所以放弃了索引来检索
05-21 redis 可以命名
可以用user:getName , user:getSchool 这样在客户端可以基于名称聚合
06-18 java.util.concurrent
J.U.C都是建立在CAS基础上之上的,包括ReetrantLock的AbstractQueuedSynchronizer,基础又是CAS
06-25 weekhashmap
WeakHashMap的Key虽然是弱引用,但是其Value却持有Key中对象的强引用,Value被Entry引用,Entry被WeakHashMap引用,最终导致Key无法回收
07-05 mysql整形长度含义
整型"的长度并不会限制存储的数字范围.
比如, int 和 int(3) 的存储范围都是 -2147483648 ~ 2147483647,
int unsigned 和 int(3) unsigned 的存储范围都是0 ~ 4294967295.
"整型"的长度实际上可以理解为"显示长度", 如果该字段开启 "Zerofill/补零"就能很明显地知道它的作用.
MySQL要求一个行定义长度不能超过65535个字节,不包括text、blob等大字段类型,varchar长度受此长度限制,
和其他非大字段加起来不能超过65535个字节
根据字符集,字符类型若为gbk,每个字符占用2个字节,最大长度不能超过32766,字符类型若为utf8,
每个字符最多占用3个字节,最大长度不能超过21845
超过以上限制则会报错:
drop table if EXISTS test1111;
create table test1111(
id char(255) null,
content varchar(21830) null
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
07-09 wrk http压测工具
ab -n1000 -c200 "请求路径" -n 请求次数 -c 并发数
wrk -t12 -c400 -d30s http://www.baidu.com
这条命令表示,利用 wrk 对 www.baidu.com 发起压力测试,线程数为 12,模拟 400 个并发请求,持续 30 秒
-c, --connections <N> 跟服务器建立并保持的TCP连接数量
-d, --duration <T> 压测时间
-t, --threads <N> 使用多少个线程进行压测
-s, --script <S> 指定Lua脚本路径
-H, --header <H> 为每一个HTTP请求添加HTTP头
--latency 在压测结束后,打印延迟统计信息
--timeout <T> 超时时间
-v, --version 打印正在使用的wrk的详细版本信息
Running 30s test @ http://www.baidu.com (压测时间30s)
12 threads and 400 connections (共12个测试线程,400个连接)
(平均值) (标准差) (最大值)(正负一个标准差所占比例)
Thread Stats Avg Stdev Max +/- Stdev
(延迟)
Latency 386.32ms 380.75ms 2.00s 86.66%
(每秒请求数)
Req/Sec 17.06 13.91 252.00 87.89%
Latency Distribution (延迟分布)
50% 218.31ms
75% 520.60ms
90% 955.08ms
99% 1.93s
4922 requests in 30.06s, 73.86MB read (30.06s内处理了4922个请求,耗费流量73.86MB)
Socket errors: connect 0, read 0, write 0, timeout 311 (发生错误数)
Requests/sec: 163.76 (QPS 163.76,即平均每秒处理请求数为163.76)
Transfer/sec: 2.46MB (平均每秒流量2.46MB)
参考网址:
https://www.cnblogs.com/quanxiaoha/p/10661650.html
08-12 httpclient url转义
如果请求的URl里面包含特殊字符或者空格或导致请求时候404,例如"//"
https://xxx/biz/test//8f5ff5bd1ac48d94149acda39c06fba8u=2160339896,1800124274?x-oss-process=image/info
解决方式,将//转义成/%2F
如果使用spring的 resttemplate 需要去除encode
RestTemplate restTemplate = new RestTemplate(httpRequestFactory);
DefaultUriBuilderFactory uriFactory = new DefaultUriBuilderFactory();
uriFactory.setEncodingMode(DefaultUriBuilderFactory.EncodingMode.NONE);
restTemplate.setUriTemplateHandler(uriFactory);
08-29 单机支持200qps接口优化
工具:arms+jmeter+arthas
1、bean拷贝会涉及到性能损耗
2、加缓冲
08-31 傻屌代码
String timeStr = datetime.getDate() +" "+ datetime.getTime()==null?"00:00:00":datetime.getTime();
测试的时候发现timeStr值都成了 datetime.getTime()都值
以后尽量避免这种写法,如果要写最好也是加括号
timeStr = datetime.getDate() +" "+( datetime.getTime()==null?"00:00:00":datetime.getTime());
09-1 mac重启后 Read-only file system
sudo mount -uw /
09-10 线程池里面异常处理
用线程池处理线程的时候,遇到异常有两种方式,
1 可以自定义异常处理,
2、线程里面的run需要加上try catch 不然异常会被吞掉。。。
09-27 单例 double check非线程安全
//private static volatile Singleton singleton3;
private static Singleton singleton3;
public static Singleton getSingleton3(){
if(singleton3==null){
synchronized (Singleton.class){
if(singleton3==null){
//非原子操作,可能导致指令重新排序
singleton3=new Singleton();
}
}
}
return singleton3;
}
//正常的 new Singleton();
memory =allocate(); //1:分配对象的内存空间
ctorInstance(memory); //2:初始化对象
instance =memory; //3:设置instance指向刚分配的内存地址
//发生指令重排后 new Singleton();
memory = allocate(); //1:分配对象的内存空间
instance = memory; //2:设置instance指向刚分配的内存地址
ctorInstance(memory); //3:初始化对象
10-26 java中逗号分隔的字符串和List相互转换
String str = StringUtils.join(list.toArray(), ",");
10-27 日志分组统计
日志格式类似 :
55893:9019 > POST /primary/api/v1/log/report HTTP/1.0
55922:9020 > GET /preparation/luyi/lessonPlan/query?lessonPlanId=6325 HTTP/1.0
55953:9021 > GET /test HTTP/1.1
grep -n -E '> GET|> POST' restful.log |awk '{print $4}'| sort |uniq -c| sort -rn
统计之后类似:
[dev-user@seg-prod-docker03 seg-primary-preparation-luyi]$ grep -n -E '> GET|> POST' restful.log |awk '{print $4}'| sort |uniq -c| sort -rn
1316 /test
162 /primary/api/v1/log/report
95 /preparation/luyi/getMasterPreparationTeacher
52 /preparation/luyi/getPreparationIndexProfile
11-03 SpringCloud服务的平滑上下线
https://zhuanlan.zhihu.com/p/84834062
https://blog.csdn.net/lc0817/article/details/54375802
https://www.cnblogs.com/gitveio/p/9207202.html
服务下线之后,客户端如何无感切换
说白了就一件事,怎样尽量缩短服务下线后Zuul和其他被依赖服务的发现时间,并在这段时间内保证请求不失败
一、Eureka的两层缓存问题
EurekaServer默认有两个缓存,一个是ReadWriteMap,另一个是ReadOnlyMap。
有服务提供者注册服务或者维持心跳时时,会修改ReadWriteMap。
当有服务调用者查询服务实例列表时,默认会从ReadOnlyMap读取
( 这个在原生Eureka可以配置,SpringCloud Eureka中不能配置,一定会启用ReadOnlyMap读取),
这样可以减少ReadWriteMap读写锁的争用,增大吞吐量。EurekaServer定时把数据从ReadWriteMap更新到ReadOnlyMap中
二、心跳时间
服务提供者注册服务后,会定时心跳
三、调用者服务从Eureka拉列表的轮训间隔
四、Ribbon缓存
1) 禁用Eureka的ReadOnlyMap缓存 (Eureka端)
eureka.server.use-read-only-response-cache: false (最重要!!!!!)
2) 启用主动失效,并且每次主动失效检测间隔为3s (Eureka端),清理无效节点的时间间隔,默认60秒
eureka.server.eviction-interval-timer-in-ms: 3000
依赖客户端主动去上报状态,如果是kill -9关闭的客户端,服务端是无法感知客户端的状态,
但是可以通过 client端的下面的参数
eureka.instance.lease-expiration-duration-in-seconds # 续约到期时间(默认90秒)
eureka.instance.lease-renewal-interval-in-seconds # 续约更新时间间隔(默认30秒)
当client端续约到期了 会主动剔除掉这个服务的
3) 服务过期时间 (服务提供方)
eureka.instance.lease-expiration-duration-in-seconds: 15
4) 服务刷新时间配置,每隔这个时间会主动心跳一次 (服务提供方)默认30s
eureka.instance.lease-renewal-interval-in-seconds: 5
5) 拉服务列表时间间隔 (客户端)默认30s
eureka.client.registryFetchIntervalSeconds: 5
6) ribbon刷新时间 (客户端)默认30s
ribbon.ServerListRefreshInterval: 5000
11-22 大订单表如何设计
https://www.jianshu.com/p/84da619ce203
1、数据如何划分
冷热数据处理
热数据:3个月内的订单数据,查询实时性较高;
冷数据A:3个月 ~ 12个月前的订单数据,查询频率不高;
冷数据B:1年前的订单数据,几乎不会查询,只有偶尔的查询需求;
2、物理存储:
热数据: 使用mysql进行存储,当然需要分库分表;
冷数据A: 对于这类数据可以存储在ES中,利用搜索引擎的特性基本上也可以做到比较快的查询;
冷数据B: 对于这类不经常查询的数据,可以存放到Hive中;
3、分库分表带来大查询问题
例如订单表分库或者分表了,如果以用户为中心,采用userId取模,可以很方便的处理用户查单诉求,
但是对商家或产品而言,数据就比较分散,相反如果以商家或商品为中心,则用户查单比较困难
所以我们可以进行数据冗余+同步+检查
例如订单数据按照月分表,
以用户查单为例,新建用户订单表(订单表U-O),将userId取模分表,冗余一份订单数据,U-O表中的数据
可以只包含重要信息如下单时间,数量,金额,订单状态等(列表页展示)。订单详情信息可以从O表中查询
商户查单就新建用户订单表(商户订单表U-O)
12-15 zookeeper相关
https://mp.weixin.qq.com/s/XR2C-ronEHMeLtlK3T6tGw
每个节点的数据最大不能超过多少呢
为了保证高吞吐和低延迟,以及数据的一致性,znode只适合存储非常小的数据,不能超过1M,最好都小于1K
znode节点里面存储的是什么
Znode包含了「存储数据、访问权限、子节点引用、节点状态信息」
「data:」 znode存储的业务数据信息
「ACL:」 记录客户端对znode节点的访问权限,如IP等。
「child:」 当前节点的子节点引用
「stat:」 包含Znode节点的状态信息,比如「事务id、版本号、时间戳」等等
Zookeeper的特性
顺序一致性,从同一客户端发起的事务请求,最终将会严格地按照顺序被应用到 ZooKeeper 中去
ZooKeeper保证的最终一致性也叫顺序一致性,即每个结点的数据都是严格按事务的发起顺序生效的
12-22 磁盘空间打慢
df -h
排查大文件
find / -type f -size +100M -print0 | xargs -0 du -h | sort -nr # 查找"/"目录下所有大于100M的所有文件
du -sh *
du -h --max-depth=1
# 查询io次数
pidstat -d 5
2021
1-5 Spring @Transactional生效原则
1、除非特殊配置(比如使用AspectJ静态织入实现AOP),否则只有定义在public方法上的@Transactional才能生效。
2、必须通过代理过的类从外部调用目标方法才能生效。
1-10 Unix的I/O模型
https://segmentfault.com/a/1190000003063859
进程与线程
http://www.ruanyifeng.com/blog/2013/04/processes_and_threads.html
用户空间与内核空间
为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操心系统将虚拟空间划分为两部分,
一部分为内核空间,一部分为用户空间,
针对linux操作系统而言,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为内核空间,
而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF),供各个进程使用,称为用户空间
进程切换与线程切换的区别
进程是操作系统进行资源(包括cpu、内存、磁盘IO等)分配的最小单位 而线程是进程运行和执行的最小调度单位
每个进程都有自己的虚拟地址空间,进程内的所有线程共享进程的虚拟地址空间。
进程切换与线程切换的一个最主要区别就在于进程切换涉及到虚拟地址空间的切换而线程切换则不会
虚拟内存
虚拟内存是操作系统为每个进程提供的一种抽象,每个进程都有属于自己的、私有的、地址连续的虚拟内存,
当然我们知道最终进程的数据及代码必然要放到物理内存上,那么必须有某种机制能记住虚拟地址空间中的某个数据被放到了哪个物理内存地址上,
这就是所谓的地址空间映射,那么操作系统是如何记住这种映射关系的呢,答案就是页表。
虚拟地址空间切换会比较耗时
把虚拟地址转换为物理地址需要查找页表,页表查找是一个很慢的过程,因此通常使用Cache来缓存常用的地址映射,这样可以加速页表查找,
这个cache就是TLB(translation Lookaside Buffer,我们不需要关心这个名字只需要知道TLB本质上就是一个cache,是用来加速页表查找的)
。由于每个进程都有自己的虚拟地址空间,那么显然每个进程都有自己的页表,
那么当进程切换后页表也要进行切换,页表切换后TLB就失效了,cache失效导致命中率降低,
那么虚拟地址转换为物理地址就会变慢,表现出来的就是程序运行会变慢,而线程切换则不会导致TLB失效,
因为线程线程无需切换地址空间,因此我们通常说线程切换要比较进程切换块,原因就在这里
TLB
也被翻译为页表缓存、转址旁路缓存,为CPU的一种缓存,由存储器管理单元用于改进虚拟地址到物理地址的转译速度
TLB可介于 CPU 和CPU缓存之间
进程切换
CPU任何时候只能运行一个进程,当需要执行另外一个进程时候,必须要先刮起正在cpu运行当进程,恢复以前挂起当
某个进程。
从一个进程的运行转到另一个进程上运行,这个过程中经过下面这些变化:
1. 保存处理机上下文,包括程序计数器和其他寄存器。
2. 更新PCB信息。
3. 把进程的PCB移入相应的队列,如就绪、在某事件阻塞等队列。
4. 选择另一个进程执行,并更新其PCB。
5. 更新内存管理的数据结构。
6. 恢复处理机上下文。
总而言之就是很耗资源
进程的阻塞
正在执行的进程,由于期待的某些事件未发生,如请求系统资源失败、等待某种操作的完成、新数据尚未到达或无新工作做等,
则由系统自动执行阻塞原语(Block),使自己由运行状态变为阻塞状态
进程的阻塞是进程自身的一种主动行为,也因此只有处于运行态的进程(获得CPU),
才可能将其转为阻塞状态。当进程进入阻塞状态,是不占用CPU资源的
文件描述符
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。
当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,
一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统
缓存 I/O
在 Linux 的缓存 I/O 机制中,操作系统会将 I/O 的数据缓存在文件系统的页缓存( page cache )中,
也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间
缺点:
数据在传输过程中需要在应用程序地址空间和内核进行多次数据拷贝操作,这些数据拷贝带来的cpu和开销是非常大的
IO模式
对于一次IO访问(以read举例),数据会先拷贝到操作系统的内核缓冲区,然后从操作系统内核的缓冲拷贝到引用程序的地址
当read操作发生的时候,会经历两个阶段:
1、等待数据准备
2、将数据从内核拷贝到进程中
正是因为这两个阶段,linux系统产生了以下五种网络模式
- 阻塞 I/O(blocking IO)
- 非阻塞 I/O(nonblocking IO)
- I/O 多路复用( IO multiplexing)
- 信号驱动 I/O( signal driven IO)
- 异步 I/O(asynchronous IO)
阻塞 I/O
对于网络IO来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来。
这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的
在用户进程这边,整个进程会被阻塞(当然,是进程自己选择的阻塞)。
当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,
用户进程才解除block的状态,重新运行起来
blocking IO的特点就是在IO执行的两个阶段都被block了
非阻塞 I/O(nonblocking)
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error,
从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果
用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。
一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回
system call -> nodata
system call -> nodata
system call -> nodata
system call -> copy complete ->return ok
nonblocking IO的特点是用户进程需要不断的主动询问kernel数据好了没有
优点:能够在等待任务完成的时间里干其他活了(包括提交其他任务,也就是 “后台” 可以有多个任务在同时执行)。
I/O 多路复用( IO multiplexing,select, poll, epoll)
IO multiplexing就是我们说的select,poll,epoll,有些地方也称这种IO方式为event driven IO。
select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select,poll,
epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程
当用户进程调用了select,那么整个进程会被block,
而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,
select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
这个图和blocking IO的图其实并没有太大的不同,事实上,还更差一些。
因为这里需要使用两个system call (select 和 recvfrom),
而blocking IO只调用了一个system call (recvfrom)。但是,用select的优势在于它可以同时处理多个connection。
IO多路复用之select、poll、epoll详解
select,poll,epoll都是IO多路复用的机制。
I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。
但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,
也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
1、select
select函数监视文件描述符,调用后select函数会阻塞,直到有描述符就绪,或者超时,函数返回,当select函数返回后,就可以遍历描述符,找到就绪的描述符。
select的一个缺点在于单个进程能够监视的文件描述符的数量也存在最大限制,
在Linux上一般为1024,可以通过修改宏定义甚至重新编译内核的方式提升这一限制。但是这样也会造成效率的降低。
2、poll
没有最大限制(但是数量过大后性能也是会下降)。和select函数一样,poll返回后,需要轮询来获取就绪的描述符。
select和poll都需要在返回后,通过遍历文件描述符来获取已经就绪的socket。
事实上,同时连接的大量客户端在同一时刻可能只有很少的就绪状态,因此随着监视的描述符数量的增长,其效率也会线性下降。
3、epoll
相对于select和poll来说,epoll更加灵活,没有描述符限制。epoll使用一个文件描述符管理多个描述符。
1-10 C10K问题
参考文章:https://segmentfault.com/a/1190000007240744?utm_source=sf-related
C10K问题(即单机1万个并发连接问题)
最初的服务器都是基于进程/线程模型的,新到来一个TCP连接,就需要分配1个进程(或者线程)。
而进程又是操作系统最昂贵的资源,一台机器无法创建很多进程。如果是C10K就要创建1万个进程,
那么单机而言操作系统是无法承受的(往往出现效率低下甚至完全瘫痪)。如果是采用分布式系统,
维持1亿用户在线需要10万台服务器,成本巨大,也只有Facebook、Google、雅虎等巨头才有财力购买如此多的服务器
C10K问题的本质
问题本质上是操作系统的问题。对于Web1.0/2.0时代的操作系统而言, 传统的同步阻塞I/O模型都是一样的,
处理的方式都是requests per second,并发10K和100的区别关键在于CPU
创建的进程线程多了,数据拷贝频繁(缓存I/O、内核将数据拷贝到用户进程空间、阻塞), 进程/线程上下文切换消耗大,
导致操作系统崩溃,这就是C10K问题的本质!
解C10K问题的解决方案
从网络编程技术角度看,有以下思路:
一个是对于每个连接处理分配一个独立的进程/线程;
此思路技术实现会使得资源占用过多,可扩展性差
用同一进程/线程来同时处理若干连接((IO多路复用))
多路复用从技术实现上又分很多种,我们逐一来看看下述各种实现方式的优劣。
● 实现方式1:
传统思路最简单的方法是循环挨个处理各个连接,每个连接对应一个 socket,
当所有 socket 都有数据的时候,这种方法是可行的。但是当应用读取某个 socket 的文件数据不 ready 的时候,
整个应用会阻塞在这里等待该文件句柄,即使别的文件句柄 ready,也无法往下处理。
实现小结:直接循环处理多个连接。
问题归纳:任一文件句柄的不成功会阻塞住整个应用。
● 实现方式2:
select要解决上面阻塞的问题,思路很简单,如果我在读取文件句柄之前,先查下它的状态,ready 了就进行处理,
不 ready 就不进行处理,这不就解决了这个问题了嘛?于是有了 select 方案。用一个 fd_set 结构体来告诉内核同时监控多个文件句柄,
当其中有文件句柄的状态发生指定变化(例如某句柄由不可用变为可用)或超时,则调用返回。
之后应用可以使用 FD_ISSET 来逐个查看是哪个文件句柄的状态发生了变化。这样做,小规模的连接问题不大,
但当连接数很多(文件句柄个数很多)的时候,逐个检查状态就很慢了。
因此,select 往往存在管理的句柄上限(FD_SETSIZE)。同时,在使用上,因为只有一个字段记录关注和发生事件,每次调用之前要重新初始化fd_set 结构体。
intselect(intnfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds,structtimeval *timeout);
实现小结:有连接请求抵达了再检查处理。
问题归纳:句柄上限+重复初始化+逐个排查所有文件句柄状态效率不高。
● 实现方式3:poll 主要解决 select 的前两个问题:通过一个 pollfd 数组向内核传递需要关注的事件消除文件句柄上限,
同时使用不同字段分别标注关注事件和发生事件,来避免重复初始化。
实现小结:设计新的数据结构提供使用效率。
问题归纳:逐个排查所有文件句柄状态效率不高。
● 实现方式4:epoll既然逐个排查所有文件句柄状态效率不高,很自然的,
如果调用返回的时候只给应用提供发生了状态变化(很可能是数据 ready)的文件句柄,进行排查的效率不就高多了么。
epoll 采用了这种设计,适用于大规模的应用场景。实验表明,当文件句柄数目超过 10 之后,
epoll 性能将优于 select 和 poll;当文件句柄数目达到 10K 的时候,epoll 已经超过 select 和 poll 两个数量级。
实现小结:只返回状态变化的文件句柄。
问题归纳:依赖特定平台(Linux)。
因为Linux是互联网企业中使用率最高的操作系统,Epoll就成为C10K killer、高并发、高性能、异步非阻塞这些技术的代名词了。
FreeBSD推出了kqueue,Linux推出了epoll,Windows推出了IOCP,Solaris推出了/dev/poll。
这些操作系统提供的功能就是为了解决C10K问题。epoll技术的编程模型就是异步非阻塞回调,也可以叫做Reactor,
事件驱动,事件轮循(EventLoop)。Nginx,libevent,node.js这些就是Epoll时代的产物。
● 实现方式5:由于epoll, kqueue, IOCP每个接口都有自己的特点,程序移植非常困难,于是需要对这些接口进行封装,以让它们易于使用和移植,
其中libevent库就是其中之一。跨平台,封装底层平台的调用,提供统一的 API,但底层在不同平台上自动选择合适的调用。按照libevent的官方网站,libevent库提供了以下功能:当一个文件描述符的特定事件(如可读,可写或出错)发生了,或一个定时事件发生了,libevent就会自动执行用户指定的回调函数,
来处理事件。目前,libevent已支持以下接口/dev/poll, kqueue, event ports, select, poll 和 epoll。
Libevent的内部事件机制完全是基于所使用的接口的。
因此libevent非常容易移植,也使它的扩展性非常容易。
目前,libevent已在以下操作系统中编译通过:Linux,BSD,Mac OS X,Solaris和Windows。
使用libevent库进行开发非常简单,也很容易在各种unix平台上移植。一个简单的使用libevent库的程序如下:
metrics fullgc问题
堆快照里面有很多char 数组
内容基本都是“http_server_requests,application=seg-uop,exception=None,host_name=seg-test-docker02,method=POST,outcome=SUCCESS,status=200,uri=/ops/configcenter/teacher/checkschoolemployeelimit/v1:4829.132935|ms”
占用了快700m,test环境docker只有1个G
char被我们自定义的spring-boot-metrics-sdk引用,里面有个MpscLinkedQueue,Queue
里面维护了很多char数组。
解决方案目前就是去除了uop里面埋点的相关代码。
2-23
OLTP(on-line transaction processing)翻译为联机事务处理,
OLAP(On-Line Analytical Processing)翻译为联机分析处理
ETL (Extract-Transform-Load),
用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库
综合可以得出,在mysql 中 boolean = tinyint(1)
2-23 mysql boolean
MYSQL保存BOOLEAN值时用1代表TRUE,0代表FALSE,boolean在MySQL里的类型为tinyint(1),
MySQL里有四个常量:true,false,TRUE,FALSE,它们分别代表1,0,1,0
3-22 磁盘使用量递增问题查询
解决进程文件句柄泄露导致磁盘空间无法释放问题
使用df -h 一直查询不到文件的目录
overlay 99G 42G 53G 45% /var/lib/docker/overlay2/5dea826e9f75b39bb82a8bb3e54f5326d94553f9876b1b6f8aaa762751ca8ee4/merged
overlay 99G 42G 53G 45% /var/lib/docker/overlay2/95483cf7956784341c2ed07b81b7750090d1a034961e0246352690f8ef783899/merged
overlay 99G 42G 53G 45% /var/lib/docker/overlay2/f857987db467702d9eb260a1d8c5da785f8b90786c200debd5798f397336b01e/merged
原来,进程打开了一个大文件, 被删除后,并没有释放。重启进程后, 才释放。
用lsof | grep deleted查一下即可知道是哪个进程。
4-9 加密方式
对称加密
加密和解密公用一个密钥,使用对称加密时候,必须要将密钥发送给对方,如果在网络上传输,密钥很可能落入攻击人之手,
这样就失去了加密的意义了。
非对称加密
非对称加密使用一对非对称的密钥,公有密钥与私有密钥,公有密钥可以给任何人,但是私有密钥不能让其他人知道。
A用公有密钥对文章进行加密,发送给B,B再用私有密钥进行解密,这样就不用担心密钥被攻击者窃听走
非对称加密的特点是信息传输一对多,服务器只需要维持一个私钥就能够和多个客户端进行加密通信
缺点:
1、因为公钥是公开的 如果使用私钥加密的信息,黑客获取后可以用公钥解密,获取其中的内容
2、公钥不包含服务器的信息,如果在传输过程中,服务器发送给客户端的公钥存在被篡改的风险
3、非对称加密在数据加密解密过程需要消耗一定时间,降低传输效率
对称加密+非对称加密(https)
在交换密钥环节使用非对称加密方式,之后的建立通信交换报文阶段则使用对称加密方式。
发送密文的一方使用对方的公钥进行加密处理“对称的密钥”,然后对方用自己的私钥解密拿到“对称的密钥”,
这样可以确保交换的密钥是安全的前提下,使用对称加密方式进行通信。
所以,HTTPS采用对称加密和非对称加密两者并用的混合加密机制
4-15 fegin原理
https://www.jianshu.com/p/e0218c142d03
fegin封装java 各种http client请求细节,屏蔽了各种http client 请求的复杂度。
支持 httpclient okhttp ribbon等等
支持 gson jackson encoders
支持 metrics
支持 hystrix slf4j mock
fegin通过java原生动态代理方式生成实现类
1、根据接口类的注解申明规则 解析出底层的mehtodHandler(DefautInvocationHandler、HystrixInvocationHandler)
2、根据Contract协议规则,解析接口类的注解信息
3、根据requestbean 动态生成request
4、encoder包装bean