10x程序员工作法
https://time.geekbang.org/column/article/73980
程序员解决的问题,大多不是程序问题
本质复杂度与偶然复杂度,大部分情况下导致忙碌都是偶然复杂度
简单来说,本质复杂度就是解决一个问题时,无论怎么做都必须要做,
而偶然复杂度是因为选用的做事方法不当,而导致要多做的事。
如果避免可以坚守以下四个原则
1、以终为始
2、任务分解
3、沟通反馈
4、自动化
程序员是如何思考
优秀程序员的开发效率是普通程序员的 10 倍
思考框架
我现在是个什么水平:高级开发
我想达到什么水平:技术leader
我将怎样到达那个目标:管理书籍,理论与实践
四个思考原则
1、为什么要做这个特性,它会给用户带来怎样的价值?
2、什么样的用户会用到这个特性,他们在什么场景下使用,他们又会怎样使用它?
3、达成这个目的是否有其它手段?是不是一定要开发一个系统?
4、这个特性上线之后,怎么衡量它的有效性?
以终为始
一种反直觉的思维方式
就是在做事之前,先想想结果是什么样子的
想象的共同体
任何事物都要经过两次创造:一次是在头脑中的创造,也就是智力上的或者第一次创造(Mental/First Creation),
然后才是付诸实践,也就是实际的构建或第二次创造(Physical/Second Creation)。
对做软件的人来说,我们应该把“终”定位成做一个对用户有价值的软件,能够为别人带来价值,自己的价值才能体现出来。
“以终为始”的方式,不仅仅可以帮我们规划工作,还可以帮我们发现工作中的问题。
遇到事情,倒着想。
你完成了工作,为什么他们还不满意?
理解的鸿沟
DoD(Definition of Done,完成的定义)
DoD 是一个清单,清单是由一个个的检查项组成的,用来检查我们的工作完成情况。
DoD 的检查项应该是实际可检查的。
DoD 是团队成员间彼此汇报的一种机制。
在做任何事之前,先定义完成的标准
接到需求任务,你要先做哪件事
需求描述的问题
验收标准给出了这个需求最基本的测试用例,它保证了开发人员完成需求最基本的质量。
扮演不同角色的时候,我们的思考模式是不同的。
在做任何需求或任务之前,先定好验收标准。
持续集成:集成本身就是写代码的一个环节
写代码是程序员的职责,但我们更有义务交付一个可运行的软件
虽然我们在同一个时代写代码做开发,但在技术实践层面,不同的团队却仿佛生活在不同的年代。
精益创业:产品经理不靠谱,你该怎么办?
精益创业的方法论里,怎么试呢?试就要有试的方法。精益创业的方法论里,提出“开发(build)- 测量(measure)- 认知(learn)”
这样一个反馈循环。就是说,当你有了一个新的想法(idea)时,就把想法开发成产品(code)投入市场,然后,
收集数据(data)获取反馈,看看前面的想法是不是靠谱。
最小可行产品,也就是许多人口中的 MVP(Minimum Viable Product)
比如,你要做这个产品特性,
你要验证的东西是什么呢?
他要验证的目标是否有数据可以度量呢?
要解决的这个问题是不是当前最重要的事情,是否还有其他更重要的问题呢?
默认所有需求都不做,直到弄清楚为什么要做这件事
解决了很多技术问题,为什么你依然在“坑”里?
“独善其身”不是好事
虽然写的代码都一样,但你看到的是树木,人家看到的是森林,他更能从全局思考。
我并不是靠技术能力解决了问题,而是凭借对需求的理解把这个问题绕过去了。
而能想到问这样的问题,前提就是要跳出程序员角色思维,扩大自己工作的上下文。
扩大自己工作的上下文,别把自己局限在一个“程序员”的角色上
为什么说做事之前要先进行推演
对比我们的工作,多数情况下,即便目标清晰,路径却是模糊的。
在我们做软件的过程中,这两种路径所带来的差异,已经在前面的小故事里体现出来了。
一种是前期其乐融融,后期手忙脚乱;
一种是前面思前想后,后面四平八稳。我个人是推崇后一种做法的。
在动手做一件事之前,先推演一番
你的工作可以用数字衡量吗?
从数字中发现问题,让系统更稳定。
从数字上看,好的系统应该是“死水一潭”。
cat监控、埋点 在点评时候每天上班第一件事就是看监控面板
问一下自己,我的工作是不是可以用数字衡量
迭代0: 启动开发之前,你应该准备什么
迭代0:具体内容只是基本的清单
迭代1:细化过的迭代需求
根据优先级从中挑出迭代 1 要开发的需求,优先级是根据我们要完成的最小可行产品(minimum viable product,MVP)来确定的,
这个最小可行产品又是由我们在这个迭代里要验证的内容决定的。一环扣一环,我们就得到了迭代1要做的需求列表
用户界面和用户交互(视觉和交互)
1. 基本技术准备
基础技术选型和技术架构
持续集成(构建脚本,多分支代码合并,代码规范,单元测试覆盖率检查)
2. 发布准备
详细上线计划,回滚方案,
设计你的迭代 0 清单,给自己的项目做体检
答疑解惑 | 如何管理你的上级
对上级不合理的要求说“不”,这是一个思想上的转变。很多人受到传统官本位思想的影响,对上级的服从达到了不健康的程度。
勇于改变,是有效管理上级的前提条件。如果不从思想上转变,我接下来的建议都是没有价值的。
问题 1:领导要求的,无力反驳怎么办?
第一,管理上级的预期
这个过程,相当于我把自己看到的问题暴露给上级,让他选择。
第二,帮助上级丰富知识
第三,说出你的想法
问题 2:产品经理总拿老板说事,怎么办?
不合理的部分应该是他和老板去沟通的,而不是让开发团队来实现
问题 3:别人能做的,我们也要做
抄”不是问题,问题是无脑地抄
竞争对手有这个特性,他为什么要做?他做这个特性与它其他特性是怎么配合的?
我们做这个特性,在我们的产品里怎样发挥价值?
即便我们最终的结果是,做的与竞争对手一模一样,经过思考之后的“抄袭”也是一件价值更大的事。
要做什么是需求,怎么做是技术。与产品经理要确认的是,这个需求是不是合理,该不该做。
技术上能否实现,这是开发团队要考虑的事情,并不是产品经理说事的理由。
向埃隆·马斯克学习任务分解
不同的可执行定义差别在于,你是否能清楚地知道这个问题该如何解决。
动手做一个工作之前,请先对它进行任务分解。
测试也是程序员的事吗
这种测试框架最大的价值,是把自动化测试作为一种最佳实践引入到开发过程中,使得测试动作可以通过标准化的手段固定下来。
不是用单元测试框架写的测试就是单元测试。
多写单元测试
先写测试,就是测试驱动开发吗?
TDD 测试驱动开发(Test Driven Development)
测试先行开发和测试驱动开发的差异就在重构上。
因为重构和测试的互相配合,它会驱动着你把代码写得越来越好。这是对“驱动”一词最粗浅的理解。
我的代码怎么写才是能测试的,也就是说,我们要编写具有可测试性
一个好的解决方案是尽量不写 static 方法
我们应该编写可测的代码
大师级程序员的工作秘笈
前面提到持续集成时,我们已经介绍过这个理念,如果集成是好的,我们就尽早集成,推向极限每一次修改都集成,这就是持续集成。
如果开发者测试是好的,我们就尽早测试,推向极限就是先写测试,再根据测试调整代码,这就是测试驱动开发。
如果代码评审是好的,我们就多做评审,推向极限就是随时随地地代码评审,这就是结对编程。
如果客户交流是好的,我们就和客户多交流,推向极限就是客户与开发团队时时刻刻在一起,这就是现场客户。
每当遇到一件要做的事,Kent Beck 总会先把它分解成几个小任务,记在一个清单上
,然后,才是动手写测试、写代码、重构这样一个小循环。
等一个循环完成了,他会划掉已经做完的任务,开始下一个。
很多人看了一些 TDD 的练习觉得很简单,但自己动起手来却不知道如何下手。中间就是缺了任务分解的环节。
一个经过分解后的任务,需要关注的内容是有限的,我们就可以针对着这个任务,把方方面面的细节想得更加清晰。
主分支开发模式可以用到 Feature Toggle,也就是说在不改变代码逻辑的情况下,增加一些开关,来隐藏或者实现功能。
将任务拆小,越小越好。!!!!
一起练习:手把手带你分解任务
每做完一个任务,代码都是可以提交的
按照完整实现一个需求的顺序去安排分解出来的任务
程序员也可以“砍”需求吗
INVEST 原则
Independent,独立的。
Negotiable,可协商的。
Valuable,有价值的。
需求管理:太多人给你安排任务,怎么办
艾森豪威尔矩阵
按照时间管理的理念,重要且紧急的事情要立即做。重要但不紧急的事情应该是我们重点投入精力的地方。
紧急但不重要的事情,可以委托别人做。不重要不紧急的事情,尽量少做。
如果不把精力放在重要的事情上,到最后可能都变成紧急的事情。
为什么世界和你的理解不一样
我们努力地学习各种知识,为的就是更好地理解这个世界的运作方式,而沟通反馈,就是我们与真实世界互动的最好方式。
这几乎是很多程序员讲东西的通病:讲东西直奔细节
轻量级沟通:你总是在开会吗?
1、所以,改善会议的第一个行动项是,减少参与讨论的人数。
2、如果你要讨论,找人面对面沟通
3、多面对面沟通,少开会
可视化:一种更为直观的沟通方式
技术雷达 http://insights.thoughtworkers.org/
看板 敏捷开发
快速反馈:为什么你们公司总是做不好持续集成
做好持续集成的关键在于,快速反馈。
开发中的问题一再出现,应该怎么办
复盘
回顾会议
5 个为什么
定期复盘,找准问题根因,不断改善
尽早暴露问题: 为什么被指责的总是你
Fail Fast
事情往前做,有问题尽早暴露。
你的代码是怎么变混乱的
单一职责原则(Single responsibility principle,SRP)
开放封闭原则(Open–closed principle,OCP)
Liskov 替换原则(Liskov substitution principle,LSP)
接口隔离原则(Interface segregation principle,ISP)
依赖倒置原则(Dependency inversion principle,DIP)
如果说设计模式是“术”,设计原则才是“道”
单一职责原则可以用在不同的层面,写一个类,你可以问问这些方法是不是为一类 actor 服务;
写方法时,你可以问问这些代码是不是在一个层面上;甚至一个服务,也需要从业务上考虑一下,
它在提供是否一类的服务。总之,你看到的粒度越细,也就越能发现问题。
面对遗留系统,你应该这样做
分清现象与根因
遗留系统和烂代码到底是不是问题呢?其实并不是,它们只是现象,不是原因
确定方案
先尝试重构你的代码,尽可能在已有代码上做小步调整,不要走到大规模改造的路上,因为重构的成本是最低的。
改造遗留系统,一个关键点就是,不要回到老路上
我们应该如何保持竞争力
成为 T 型人!!!!
什么叫 T 型人?简言之,一专多能,知识的广度和专业能力的深度,这里的“专”不是熟练,而是深入
在学习区工作和成长
工作中不要满足当前需求,要经常从自己上级主管甚至老板角度来审视自己的工作,思考业务的终极目标,持续琢磨扩展边界,挑战工作难度
平时多看书多思考,除了钻研某个领域,还要多有涉猎,拓展领域,成为终身学习者。
适当运动维持健康,你有更多体力和更强抗压能力的时候,就可以超过不少人。
保持竞争力除了上述之外,要保持乐观,相信大多数事都有解决方法,在多数人都容易放弃的时候,你的坚持,就是竞争力。
书单
《敏捷软件开发:原则、实践与模式》
《架构整洁之道》
《测试驱动开发》
《The Practice of Programming》
《领域驱动设计精粹》
《分析模式》
https://www.douban.com/doulist/112766085/
代码精进之路
从条件运算符说起,反思什么是好代码
坚持使用最直观的编码方式,而不是追求代码简短
容易理解;
没有明显的安全问题;
能够满足最关键的需求;
有充分的注释;
使用规范的命名
把错误关在笼子里
1、提高程序员的修养
2、编译器
3、回归测试
4、代码评审
5、代码分析工具
写好声明的“八项纪律”
一行一个声明
局部变量需要时再声明
类属性要集中声明
怎么用好Java注解?
Override、继承重写
Deprecated、废弃 @Deprecated(since="1.2", forRemoval=true)
SuppressWarnings
异常处理都有哪些陷阱
处理好捕获异常
Exception 类是一个包罗万象的超级异常类,如果我们使用 Exception 作为声明和抛出的异常,
就不方便用户精准定位,从而解读和判断“出了什么错”。 类似的超级异常类还有 RuntimeException、IOException 等。
除非是超级的接口,否则我们应该尽量减少超级异常类的使用,而是选择那些意义明确、覆盖面小的异常类,
比如 FileNotFoundException。
编写规范代码的检查清单
技术管理实战36讲
外驱让我们可以做好本职工作,而内驱才能让我们成就卓越。
哪些人比较容易走上管理岗位?
天时:
做管理的“天时”,其实就是机会、时机、大环境、时代背景。
地利:
管理的“地利”,就是你的优势、能力,以及你所负责的工作内容。
第一类是负责最全局的模块,核心是“广”
第二类是负责最核心的技术模块,核心是“深”
人和:
做管理的“人和”,就是你能否得到他人的支持
左耳听风
技术变现
1.通过在公司工作提高自己的技能,让自己可以更为独立和自由地生活。
2.对于没什么技术含量的工作内容,提高交付效率。把时间用来研究高技术含量的知识。
3.要写文章就写别人没有写过的,或是别人写过,但我能写得更好的。
4.看清市场需求(各个公司正在做什么,难题是什么)和技术趋势(首先要了解技术的历史,把本质吃透:看经典书籍,向前沿学习)
5.在学习技术的过程一定要多问自己两个问题:“一,这个技术解决什么问题?为什么别的同类技术做不到?
二,为什么是这样解决的?有没有更好的方式?”另外,还有一个简单的判断方法,
如果一个新的技术顺应技术发展趋势,那么在这个新的技术出现时,后面一定会有大型的商业公司支持(专门做此类技术的公司),
这类公司支持得越多,就说明你越需要关注。
6.在一家高速发展的公司中,技术人员的价值可以达到最大化。比较好的成长路径是,
先进入大公司学习大公司的技术和成功的经验,然后再找到高速成长的公司,这样你就可以实现自己更多的价值。
7.动手能力很重要,持续在前线工作。
8.关注技术付费点:一个是,能帮别人“挣钱”的地方;另一个是,能帮别人“省钱”的地方。
9.提高自己的能力和经历。
找到有价值的信息源(知识的源头:西方世界)
10.输出观点和价值观,只有输出了更先进的价值观,才会获得真正的影响力(厚积薄发的过程)
11.优质的朋友圈。
技术领导力
1、能够发现问题
2、能够提供解决问题的思路和方案、并且比较这些方案优缺点
3、能够做出正确的技术决定(用什么技术、什么解决方案、怎么样完成一个项目)
4、能够用更优雅更简单更容易的方式来解决问题
5、能够提高代码活着软件的扩展性、重用性和可维护性
以后做任何的事情千万不要做临时方案,临时方案就是给自己挖坑
重用性就是考虑抽离多个组件
可维护就是考虑到怎么样去设计系统架构和代码的模块化,系统之间的边界线
6、能够用正确的方式管理团队
让正确的人做正确的事情,提高团队的生产力和人效率,找到最有价值的需求并且用最小的成本实现。
7、创新能力
如何成为拥有技术领导力或者拥有技术领导力的人都有哪些共同点
1、扎实的基础技术
第一,你要吃透基础技术。基础技术是各种上层技术共同的基础
2、非同一般的学习能力
第二,提高学习能力。所谓学习能力,就是能够很快地学习新技术,又能在关键技术上深入的能力
google\stack overflow quora
3、坚持做正确的事情
提高效率、自动化的事情、掌握前沿技术的事、知识密集型的事、技术驱动的事
4、不断提高对自己的要求标准
强调实践、学以致用。
异常处理
不推荐在循环体里处理错误
不要把大量的代码都放在一个 try 语句块内
错误日志的输出最好使用错误码,而不是错误信息
时间管理
主动管理,封闭式开发
学会说不
我不能说不,但是我要有条件地说是。而且,我要把你给我的压力再反过来还给你,
看似我给了需求方选择,实际上,我掌握了主动
投资自己的时间
系统的学习一门技术
花时间在解放自己的事情上,比如过度设计
规划自己的时间
1、定义好优先级
2、最短作业优先
3、想清楚再做
4、关注长期利益规划
阿甘老师管理方法论整理
https://note.youdao.com/ynoteshare1/index.html?id=807acbd1ebf56f06d429152a1d18768e&type=note
管理最有效能的事情还是让团队成长和提升
人是企业最重要资产也是最重要的产品,就是要靠企业来培养
过程比结果更重要。对。掌握正确的过程才能复制出好的结果,凡夫畏果,菩萨畏因
管理6个基本动作
沟通、辅导、激励、授权、review 、执行
领导力四要素
客户第一、以身作则、愿景驱动、挑战现状
技术人的灵魂3问,阿里工程师如何解答?
如何在业务中发现有技术价值的问题?
业务开发对业务对理解可能局限自己做的事情,很多信息都是过滤了五六手,得到的可能就是做这个任务和为什么做这个任务,
相比之下肯定不如制定战略的人懂得战略背后的意义,信息也是不对等,所以要收集信息,整理归纳,最后分析问题
收集信息
各个bu大佬的okr与周报
分析问题
可以使用MECE法则进行思考拆解,通过无遗漏无重复地分类来把握整体,列出脑图和逻辑树,
最后将逻辑树的信息匹配需求场景,可以尝试通过C端和B端不同入口去还原需求场景。
这中间可以结合一定的方法论(演绎推理和归纳推理),去把问题和挑战细化出来,帮助我们理解BU的战略,
同时我们也能从自身出发把战略拆解到对应的项目
发现问题到执行该如何衔接
发现问题后不能马上就开始做,要提炼问题带来的核心价值,否则投入巨大工作之后,技术产品与业务结果衔接不上
思考不要用蛮力,工作不只靠体力
见龙在田,利见大人,资源有限情况找对的人,拆关键词找到做事情的关键人
最后的技术结果跟业务结果如何衔接
在业务做开发,重复造轮子会被人挑战,但事情都有人干了我们的价值在哪?
所以我们在业务端需要的是有技术视野能看到集团其他团队或者外部团队在做的事,能主动交流让这件事变成共赢,
如果没有其他人在搞,我们去搞要有人站出来看这个投入产出比是否合理?
也就是我们在开篇说的议题度和解答质都高的有价值的问题。
这个问题在集团其他团队是否存在共性,我们解决了能否为他们带来价值?
当然结合我们在前面讲到的在业务中发现有技术价值的问题,其实这里就有一个比较明确的答案
重中之重就是做之前把Why思考的清楚清晰,做最正确的事。只有做到这点,解决这个问题带来的业务价值就自然而然非常清晰的定位出来。
所以说最好的工程师必须要懂产品
也是说最好不要让业务推着你走,而是最终要做到你带着业务走
推荐书籍
《金字塔原理》、《麦肯锡教我的思考武器》、《思考,快与慢》、《影响力》、《自控力》、《敏捷性开发》。
程序员的成长路线Remix(HelloJava公众号)
https://mp.weixin.qq.com/s/JIJCG_NvrZyL0IYNkDkAuA
编程能力的成长
编程能力初级:会用
初级这个阶段对于大部分程序员来说都不会是问题,勤学苦练,是这个阶段的核心编程能力中级:会查和避免问题
在查问题的能力上,首先要掌握的是一些基本的调试技巧,好用的调试工具, 就像在Java里JDK自带的jstat、jmap、jinfo,不在JDK里的mat、gperf、btrace等 成为一个能写出高质量代码、有效排查问题的优秀程序员编程能力高级:懂高级API和原理
例如学Java NIO,可以自己基于NIO包一个框架,然后对比Netty,看看哪些写的是不如Netty的,这样会非常有助于真正的理解 Java的编译机制、内存管理、线程机制 1万小时理论系统设计能力的成长
整个系统的目标、模块的划分和职责、关键的对象设计 先在一两个技术领域做到专业,然后尽量扩大自己的知识广度
我在Uber运营大型分布式系统三年经验谈(InfoQ公众号)
https://mp.weixin.qq.com/s/TIGI4cI3jt_djbm6Iu8W7g
大型分布式系统经验
一、监控
1、基础设施监控
2、服务健康监控,流量,错误,延迟
3、业务指标监控
二、值班,异常检测和告警
三、停服务器与事件管理流程
1、回滚
四、事后总结
caseStudy
五、有计划的的服务宕机演习,容量规划
六、slo与sla
Service level objective 系统可用性数字化指标
包括。容量目标,延迟,准确度,可用性
自动化测量报告,
项目管理实战20讲
一、角色转换误区
1.1 凡事恨不得事必躬亲
让人知道要做(Awareness)
有动力做(画大饼,讲清楚为什么要做,为什么要现在做,获取团队动力)
和有能力做(积极争取外部资源)
1.2 追在别人屁股后面做监工
要明确目标,建立机制,并让这个机制运转起来,最终在项目组形成一种良性的秩序
1.3 拿着锤子,看哪里都是钉子
时间、成本、质量、范围这几个因素,到底哪个更重要?哪些是允许有一定调整空间的?
二、十大领域
2.1 干系人管理:如果管理干系人
2.2 范围管理:做什么
2.3 进度管理:花多长时间
2.4 成本管理:花多大代价
2.5 质量管理:达到什么要求
2.6 资源管理:有多少内部资源
2.7 采购管理:有多少需要买
2.8 沟通管理: 如何管理沟通
2.9 风险管理:如何应对风险
2.10 整合管理: 如何实现整体最优
三、五大过程
质量管理领域PDCA:做任何事情都要经过Plan、执行Do、检查Check、行动Act,PMI遵循PDCA的法则。
3.1 项目启动过程组
项目启动时候拉所有人开会,设定愿景目标和重要里程碑,确定责任分工和沟通机制
3.2 规划过程组
把愿景目标转化为可落地的行动方案和工作路线
3.3 执行过程组
根据规划执行
3.4 监控过程组
提前预知风险,及时调整
3.5 收尾过程组
复盘
项管职责定位:
保目标、助决策、提效能、促协作
四 启动-识别项目中的四类干系人
如果按照在项目上的权力和利益相关度对干系人进行划分,可以把项目干系人分成以下四类:
高利益高权力,高利益低权力,低利益高权力,低利益低权力。
4.1 高利益高权力:项目发起人
项目发起人称为Sponsor,即项目资助人,需要重点管理。因为很多项目执行过程中突然夭折
就是因为还没清晰定位项目会为组织带来什么,以及组织对项目成功的定义。
沟通模版例如:他发起这个项目的背景和初衷是什么?如何才能知道我们做到了?哪些资源是项目获得成功的关键?
他最看重项目的哪些要素?是进度、质量、成本还是范围?在极端情况下,我们该如何对这些要素进行排序呢?
4.2 低利益高权力:职能经理
职能经理是资源池的所有者,他们所管辖的团队通常覆盖多个项目或项目群,这也使得他们与单个项目的利益相关度通常比较低,
介入程度往往也很有限。
对项目的态度可以分为以下三部分
反对者
管理这类人的重点在于建立信任,化解敌意
支持者
支持者是项目获取成功非常依赖的力量,管理这些人就是,让他们深度参与到项目
,提高他们的主人翁意识。
中立者
在条件合适时,进一步将其转化为支持力量。但如果你精力有限,可以先不管。
4.3 “高利益低权力”代表:项目组成员
与项目结果直接相关、但对决策影响不大的一类人
管理这类人的核心就是做到项目事项随时告知,及时通报项目的进度和困难
4.4 “低利益低权力”代表:外围支持人员
俗称外包,技术外包或者设计外包。对于这些人提前约定好,每天或者每周进展汇报的格式和内容。
五、规划-排除计划中的延期地雷
计划是贯穿始终的重要课题,是各个角色协同工作的基准,做计划,是个集体对焦的过程
5.1 雷区1:不够具体
例如xx项目计划于3月20日提测,4月1日上线。
解决方式:WBS工作分解,创建WBS的过程,也就是把项目工作按阶段可交付成果分解成较小的、更易于管理的组成部分的过程。
简单来说,WBS就是“把大象放进冰箱”的过程。
5.2 雷区2:不够全面
只有任务列表,没有识别关键资源和关键依赖,也没有考虑研发之外其他环节,是不够全面的
5.3 雷区3:不够准确
定义完成标准,防止大家磨嘴皮子。越早定义完成标准,计划按照期望完成的概率就越大
例如 需求或者设计确认、功能完成或者提测(冒烟测试通过率高于90%)、里程碑完成(如不存在P0及P1优先级的Bug
5.4 雷区4:没有共识
没有达成共识的计划,是不具备任何效力的。
在确认计划之后,向所有项目组成员,包括项目的所有干系人,发送计划邮件,正式周知,这可以尽早地发现共识的偏差。
5.5 雷区5:不够及时
每一次进行调整,都要确保项目中的每个人知道当前的计划是什么,调整计划需要怎样的决策过程,都需要谁参与决策。
而及时调整变更,就是做计划的第五个标准动作。
六、执行-打造品质、要从头开始”闭环“
其实就是做到以终为始,构建系统能力,在产品研发的整个过程中,建立起真正闭环反馈的产品验证机制
6.1 方案评审
需求评审、交互评审、视觉评审
6.2 BugBash(Bug大扫除)
项目末期集中找bug
6.3 冒烟用例评审
从测试人员记录冒烟测试通过率开始
七、监控-进展“巧”汇报,学会用数据说话
7.1 紧急报告模版
事件描述;影响后果;跟进分析;响应措施:包含负责人及时间表;所需支持。
7.2 常规汇报
八、项目复盘
8.1 复盘基调
复盘不等于追责,而是集体进入反思。
这次复盘不是来挑问题的,而是为了找到问题的根源并改进的
8.2 复盘会流程
1、现场回顾项目情况,例如目标达成情况、进度计划变更情况、需求变更情况、质量报告
2、参会人员写下项目过程中做的好的以及做的不好的3点,然后汇总贴白板
3、在白板前review大家的意见
4、对大家总结出的好与不好点投票
5、整理投票结果,对于好的环节,总结经验;对于不好环节,当初做出改进方案。
8.3 打造团队持续改进能力
激发团队的主人翁意识,让团队成为复盘的主角,而不是你。
九、需求变更
9.1 达成最小共识,变更是有代价的
9.2 源头治理,一次把事情做对
9.3 快试错,不可抗力巧应对
DDD实战课
1、领域驱动设计:微服务设计为什么要选择DDD
微服务拆分困境产生的根本原因就是不知道业务或者微服务的边界到底在什么地方
DDD 核心思想是通过领域驱动设计方法定义领域模型,从而确定业务和应用边界,
保证业务模型与代码模型的一致性, DDD设计方法作为微服务的主流设计方法
DDD不是架构,而是一种架构设计方法论,它通过边界划分将复杂业务领域简单化,
帮我们设计出清晰的领域和应用边界,可以很容易地实现架构演进
DDD是一种架构设计方法,微服务是一种架构风格,两者从本质上都是为了追求高响应力,
而从业务视角去分离应用系统建设复杂度的手段。两者都强调从业务出发,
其核心要义是强调根据业务发展,合理划分领域边界,持续调整现有架构,
优化现有代码,以保持架构和代码的生命力,也就是我们常说的演进式架构
战略设计
战略设计主要从业务视角出发,建立业务领域模型,划分领域边界,
建立通用语言的限界上下文,限界上下文可以作为微服务设计的参考边界
领域模型可以用来指导微服务的设计和拆分
事件风暴是建立领域模型的主要方法,是个发散到收敛到过程
采用用例分析、场景分析、用户旅程分析,梳理领域对象之间到关系,这是个发散等过程,
会产生很多实体,命令,事件等领域对象,我们再将这些对象进行不同纬度进行聚类,形成
聚合、限界上下文等边界,建立领域模型就是一个收敛等过程
战术设计
战术设计则从技术视角出发,侧重于领域模型的技术实现,完成软件开发和落地,
包括:聚合根、实体、值对象、领域服务、应用服务和资源库等代码逻辑的设计和实现
三步划定领域模型和微服务的边界
1、在事件风暴中梳理业务过程中的用户操作、事件、以及外部依赖关系,根据这些要素梳理出
领域实体等领域对象
2、根据领域实体之间等业务关联性,将业务紧密相关的实体进行组合形成聚合,同时确定
聚合中的聚合根、值对象和实体,聚合之间的边界是第一层边界,一般用虚线表示,它们是
在同一个服务实例中运行,属于逻辑边界
3、根据业务或者语意边界,将一个或者多个聚合划定在一个限界上下文中,形成领域模型,
限界上下文之间的边界可以定义成未来微服务的边界,不同限界上下文的领域逻辑被隔离
在不同的实例,属于物理边界。
2、领域、子域、核心域、通用域、支撑域
如何理解领域与子域
领域就是用来确定范围的,范围就是边界
ddd会按照一定的规则将业务领域进行细分,当领域细分到一定程度后,
会将问题限定在特定的边界内,在这个边界内建立领域模型,
进而用代码实现该领域模型,解决相应的业务问题
领域可以划分为多个子领域,每个子领域对应一个更小的问题或者更小的业务范围
如何理解核心域、通用域和支撑域
决定产品和公司核心竞争力的子域是核心域,它是业务成功的主要因素和公司的核心竞争力。
通用域则是你需要用到的通用系统,比如认证、权限等等
支撑域则具有企业特性,但不具有通用性,例如数据代码类的数据字典等系统
3、限界上下文:定义领域边界的利器
通用语言
从事件风暴建立通用语言到领域对象设计和代码落地的完整过程。
事件风暴-->领域故事分析-->提取领域对象-->领域对象与代码模型映射-->代码落地
什么是限界上下文?
语言都有它的语义环境,同样,通用语言也有它的上下文环境。
为了避免同样的概念或语义在不同的上下文环境中产生歧义,DDD在战略设计上提出了“限界上下文”这个概念,
用来确定语义所在的领域边界
限界和上下文。限界就是领域的边界,而上下文则是语义环境。
用来封装通用语言和领域对象,提供上下文环境,保证在领域之内的一些术语、业务相关对象等
(通用语言)有一个确切的含义,没有二义性
限界上下文和微服务的关系
理论上限界上下文就是微服务的边界。我们将限界上下文内的领域模型映射到微服务,就完成了从问题域到软件的解决方案。
子域还可根据需要进一步拆分为子子域,拆到一定程度后,有些子子域的领域边界就可能变成限界上下文的边界了
子域可能会包含多个限界上下文,有些子域本身的边界就是限界上下文边界,
正如电商领域的商品一样,商品在不同的阶段有不同的术语,在销售阶段是商品,
而在运输阶段则变成了货物。同样的一个东西,由于业务领域的不同,
赋予了这些术语不同的涵义和职责边界,这个边界就可能会成为未来微服务设计的边界。
4、实体和值对象
实体是指有延续性或者是唯一标示
值对象 值对象的属性值是不允许变化的,即值对象的实体在创建之后就不会变了,
如果要改变其属性值,就需要先把此对象删除,然后重新创建一个新对象
实体
拥有唯一标识符,且标识符在历经各种状态变更后仍能保持一致。对这些对象而言,
重要的不是其属性,而是其延续性和标识,对象的延续性和标识会跨越甚至超出软件的生命周期。
1.实体的业务形态
在战略设计时,实体是领域模型的一个重要对象。领域模型中的实体是多个属性、操作或行为的载体。
在事件风暴中,我们可以根据命令、操作或者事件,找出产生这些行为的业务实体对象,
进而按照一定的业务规则将依存度高和业务关联紧密的多个实体对象和值对象进行聚类,形成聚合
实体和值对象是组成领域模型的基础单元
2.实体的代码形态
在DDD里,这些实体类通常采用充血模型,与这个实体相关的所有业务逻辑都在实体类的方法中实现,
跨多个实体的领域逻辑则在领域服务中实现。
3.实体的运行形态
实体以DO(领域对象)的形式存在,每个实体对象都有唯一的ID
4.实体的数据库形态
与传统数据模型设计优先不同,DDD是先构建领域模型,针对实际业务场景构建实体对象和行为,
再将实体对象映射到数据持久化对象
一个实体可能对应0个、1个或者多个数据库持久化对象
值对象
在DDD中用来描述领域的特定方面,并且是一个没有标识符的对象,叫作值对象
人员实体原本包括:姓名、年龄、性别以及人员所在的省、市、县和街道等属性。
这样显示地址相关的属性就很零碎了对不对?现在,我们可以将“省、市、县和街道等属性”
拿出来构成一个“地址属性集合”,这个集合就是值对象了
1.值对象的业务形态
实体具有业务属性、业务行为和业务逻辑。而值对象只是若干个属性的集合,
只有数据初始化操作和有限的不涉及修改数据的行为,基本不包含业务逻辑
2.值对象的代码形态
值对象在代码中有这样两种形态。
如果值对象是单一属性,则直接定义为实体类的属性;
如果值对象是属性集合,则把它设计为Class类,Class将具有整体概念的多个属性归集到属性集合,
这样的值对象没有ID,会被实体整体引用
3.值对象的运行形态
值对象嵌入到实体的话,有这样两种不同的数据格式,也可以说是两种方式,分别是属性嵌入的方式和序列化大对象的方式
从代码层次来说属性嵌入式其实就是成员变量属性,序列化方式可以理解成引入一个成员变量对象。
4.值对象的数据库形态
在领域建模时,我们可以将部分对象设计为值对象,保留对象的业务涵义,同时又减少了实体的数量;
在数据建模时,我们可以将值对象嵌入实体,减少实体表的数量,简化数据库设计。
例如:人员和地址那个场景
地址作为值对象,人员作为实体,这样就可以保留地址的业务涵义和概念完整性。
而在数据建模时,我们可以将地址的属性值嵌入人员实体数据库表中,只创建人员数据库表。
这样既可以兼顾业务含义和表达,又不增加数据库的复杂度。
5.值对象的优势和局限
值对象采用序列化大对象的方法简化了数据库设计,减少了实体表的数量,可以简单、清晰地表达业务概念
。这种设计方式虽然降低了数据库设计的复杂度,但却无法满足基于值对象的快速查询,
会导致搜索值对象属性值变得异常困难
6.实体和值对象的关系
值对象和实体在某些场景下可以互换
有些场景中,地址会被某一实体引用,它只承担描述实体的作用,并且它的值只能整体替换,
这时候你就可以将地址设计为值对象,比如收货地址。而在某些业务场景中,地址会被经常修改,
地址是作为一个独立对象存在的,这时候它应该设计为实体,比如行政区划中的地址信息维护
05-聚合和聚合根:怎样设计聚合?
聚合有一个聚合根和上下文边界,这个边界根据业务单一职责和高内聚原则,
定义了聚合内部应该包含哪些实体和值对象,而聚合之间的边界是松耦合的。
按照这种方式设计出来的微服务很自然就是“高内聚、低耦合”的
聚合在DDD分层架构里属于领域层,领域层包含了多个聚合,共同实现核心业务逻辑。
聚合内实体以充血模型实现个体业务能力,以及业务逻辑的高内聚。
聚合根
如果把聚合比作组织,那聚合根就是这个组织的负责人。
聚合根也称为根实体,它不仅是实体,还是聚合的管理者
首先它作为实体本身,拥有实体的属性和业务行为,实现自身的业务逻辑。其次它作为聚合的管理者,
在聚合内部负责协调实体和值对象按照固定的业务规则协同完成共同的业务逻辑。最后在聚合之间,
它还是聚合对外的接口人,以聚合根ID关联的方式接受外部任务和请求,在上下文内实现聚合之间的业务协同。
也就是说,聚合之间通过聚合根ID关联引用,如果需要访问其它聚合的实体,
就要先访问聚合根,再导航到聚合内部实体,外部对象不能直接访问聚合内实体。
怎样设计聚合
DDD领域建模通常采用事件风暴,它通常采用用例分析、场景分析和用户旅程分析等方法,
通过头脑风暴列出所有可能的业务行为和事件,然后找出产生这些行为的领域对象,
并梳理领域对象之间的关系,找出聚合根,找出与聚合根业务紧密关联的实体和值对象,
再将聚合根、实体和值对象组合,构建聚合
聚合根的特点:聚合根是实体,有实体的特点,具有全局唯一标识,有独立的生命周期。
一个聚合只有一个聚合根,聚合根在聚合内对实体和值对象采用直接对象引用的方式进行组织和协调,
聚合根与聚合根之间通过ID关联的方式实现聚合之间的协同。
实体的特点:有ID标识,通过ID判断相等性,ID在聚合内唯一即可。
状态可变,它依附于聚合根,其生命周期由聚合根管理。
实体一般会持久化,但与数据库持久化对象不一定是一对一的关系。
实体可以引用聚合内的聚合根、实体和值对象。
值对象的特点:无ID,不可变,无生命周期,用完即扔。值对象之间通过属性值判断相等性。
它的核心本质是值,是一组概念完整的属性组成的集合,用于描述实体的状态和特征。值对象尽量只引用值对象。
聚合的一些设计原则
总结:
一个事物只能修改一个聚合、聚合要小,聚合关联其他聚合的唯一标示,
业务操作中设计多个聚合状态修改,可以改成消息模式解耦
领域服务不能跨多个聚合调用,表设计的时候也不要跨多个表关联
1.在一致性边界内建模真正的不变条件
聚合用来封装真正的不变性,而不是简单地将对象组合在一起。
在一个事务中只修改一个聚合实例
2.设计小聚合
如果聚合设计得过大,聚合会因为包含过多的实体,导致实体之间的管理过于复杂,
高频操作时会出现并发冲突或者数据库锁,最终导致系统可用性变差。
3.通过唯一标识引用其它聚合
当存在对象之间的关联时,建议引用其唯一标识而非引用其整体对象。
如果是外部上下文中的实体,引用其唯一标识或将需要的属性构造值对象。
如果聚合创建复杂,推荐使用工厂方法来屏蔽内部复杂的创建逻辑
4.在边界之外使用最终一致性
在一次事务中,最多只能更改一个聚合的状态。如果一次业务操作涉及多个聚合状态的更改,
应采用领域事件的方式异步修改相关的聚合,实现聚合之间的解耦
5.通过应用层实现跨聚合的服务调用。
为实现微服务内聚合之间的解耦,以及未来以聚合为单位的微服务组合和拆分,
应避免跨聚合的领域服务调用和跨聚合的数据库表关联。
06-领域事件:解耦微服务的关键
领域事件是对领域内发生的活动进行的建模。
领域事件是领域模型中非常重要的一部分,用来表示领域中发生的事件。
一个领域事件将导致进一步的业务操作,在实现业务解耦的同时,还有助于形成完整的业务闭环。
1.微服务内的领域事件
微服务内应用服务,可以通过跨聚合的服务编排和组合,以服务调用的方式完成跨聚合的访问,
这种方式通常应用于实时性和数据一致性要求高的场景
2.微服务内的领域事件
微服务之间的访问也可以采用应用服务直接调用的方式,实现数据和服务的实时访问,
弊端就是跨微服务的数据同时变更需要引入分布式事务,以确保数据的一致性。
领域事件总体架构
领域事件处理包括:事件构建和发布、事件数据持久化、事件总线、消息中间件、事件接收和处理等
基于mq解耦
领域事件驱动机制可以实现一个发布方N个订阅方的模式,这在传统的直接服务调用设计中基本是不可能做到的
07-DDD分层架构:有效降低层与层之间的依赖
传统的四层架构;用户接口层-->应用层--> 领域层--> 基础层
依赖倒置的四层架构:基础层--> 用户接口层--> 应用层--> 领域层
用户层
应用层
应用层是很薄的一层,理论上不应该有业务规则或逻辑,主要面向用例和流程相关的操作
应用层也是微服务之间交互的通道,它可以调用其它微服务的应用服务,完成微服务之间的服务组合和编排
领域层
领域层的作用是实现企业核心业务逻辑,通过各种校验手段保证业务的正确性。
领域层主要体现领域模型的业务能力,它用来表达业务概念、业务状态和业务规则
基础层
基础层包含基础服务,它采用依赖倒置设计,封装基础资源服务,实现应用层、领域层与基础层的解耦,
降低外部资源变化对应用的影响
在传统架构设计中,由于上层应用对数据库的强耦合,很多公司在架构演进中最担忧的可能就是换数据库了,
因为一旦更换数据库,就可能需要重写大部分的代码,这对应用来说是致命的。那采用依赖倒置的设计以后,
应用层就可以通过解耦来保持独立的核心业务逻辑。当数据库变更时,我们只需要更换数据库基础服务就可以了
,这样就将资源变更对应用的影响降到了最低
DDD分层架构最重要的原则是什么
每层只能与位于其下方的层发生耦合
架构根据耦合的紧密程度又可以分为两种:严格分层架构和松散分层架构
优化后的DDD分层架构模型就属于严格分层架构,任何层只能对位于其直接下方的层产生依赖。
而传统的DDD分层架构则属于松散分层架构,它允许某层与其任意下方的层发生依赖。
试想下,如果领域层中的某个服务发生了重大变更,那该如何通知所有调用方同步调整和升级呢?
但在严格分层架构中,你只需要逐层通知上层服务就可以了
三层架构如何演变成四层架构
三层架构向DDD分层架构演进,主要发生在业务逻辑层和数据访问层。
DDD分层架构将业务逻辑层的服务拆分到了应用层和领域层
应用层快速响应前端的变化,领域层实现领域模型的能力
另外一个重要的变化发生在数据访问层和基础层之间,三层架构数据访问采用DAO方式;
DDD分层架构的数据库等基础资源访问,采用了仓储(Repository)设计模式,通过依赖倒置实现各层对基础资源的解耦
08微服务架构模型:几种常见模型的对比和分析
整洁架构
整洁架构又名“洋葱架构,整洁架构最主要的原则是依赖原则,
它定义了各层的依赖关系,越往里依赖越低,代码级别越高,越是核心能力。
外圆代码依赖只能指向内圆,内圆不需要知道外圆的任何情况
六边形架构
六边形架构又名“端口适配器架构”。追溯微服务架构的渊源,一般都会涉及到六边形架构
网络编程实战
02 | 网络编程模型:认识客户端-服务器网络模型的基本概念
无论是客户端,还是服务器端,它们运行的单位都是进程而不是机器
保留网段:
10.x 、192.168.x、172.x
子网掩码:
网络概念:192.168.1.1~192.168.1.255
主机概念:1到255就是可用到不同ip
04 | TCP三次握手:怎么使用套接字格式建立连接
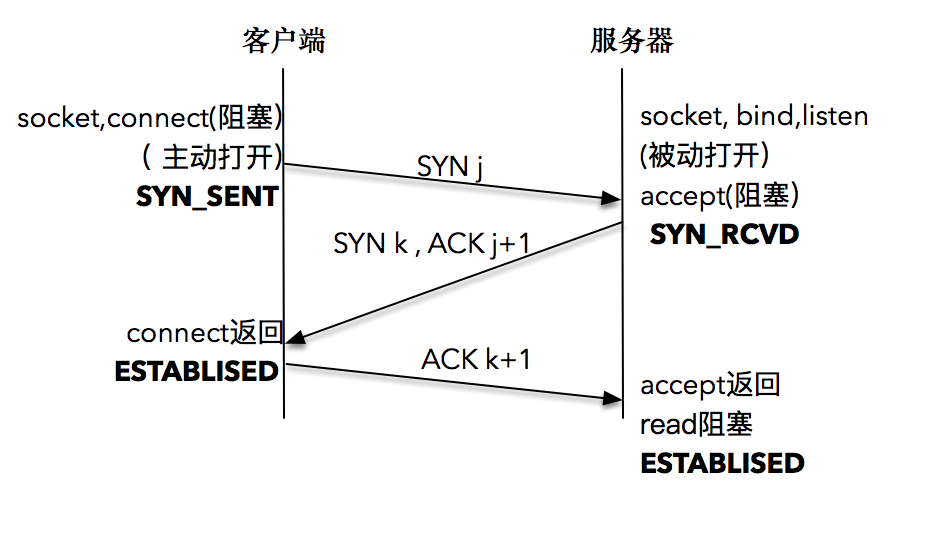
Seq: 顺序号字段
SYN:发起一个连接
ACK:确认序号有效
1、客户端向服务端发送syn包,并且告诉服务器端当前发送序号为seq=j,客户端进入sync_sent
2、服务端收到包后 进行ACK=j+1应答,同时也向客户端发送syn包 同时告诉客户端当前发送序号为seq=k,服务器进入sync_rcvd
3、客户端收到ack后检查ack是否为j+1,同时客户端因为发送应答包确认序号 ack=k+1,客户端进入established
4、服务端收到应答包后,检查ack是否为j+1,如果是就进入established
10 | TIME_WAIT:隐藏在细节下的魔鬼
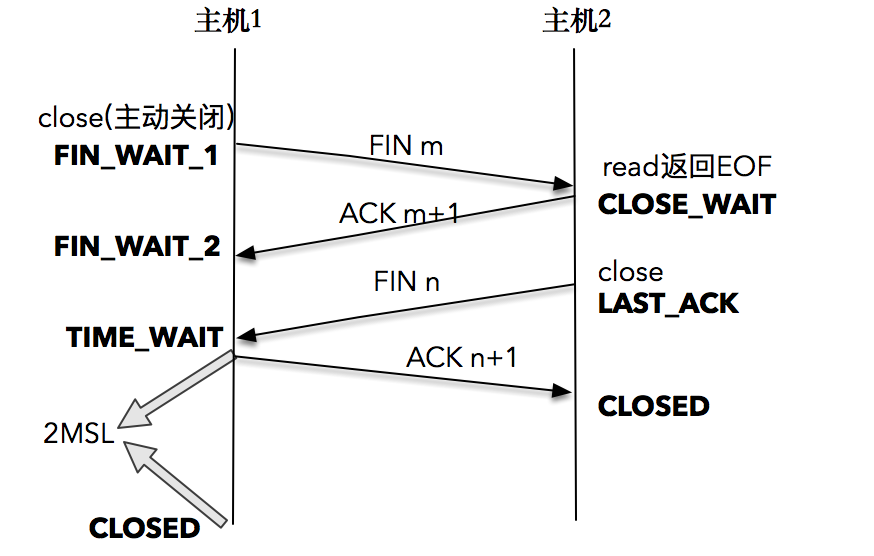
Linux 系统停留在 TIME_WAIT 的时间为固定的60s
一般都是客户端发起fin请求
只有发起连接终止的一方会进入 TIME_WAIT 状态
为什么是四次挥手不是三次挥手?
挥手的时候是server端先发送ACK 然后再发送FIN
time_wait作用,为什么client接收到ack后不马上进入closed
1、确保最后的ack能让被动关闭方接收
11 | 优雅地关闭还是粗暴地关闭 ?
如何设计一个秒杀系统
设计秒杀系统时应该注意的5个架构原则
4要1不要
1、数据尽量要少
首先是指用户请求的数据能少就少。请求的数据包括上传给系统的数据和系统返回给用户的数据
2、请求数要尽量少
例如,减少请求数最常用的一个实践就是合并CSS和JavaScript文件,把多个JavaScript文件合并成一个文件,
3、路径要尽量短
所谓“路径”,就是用户发出请求到返回数据这个过程中,需求经过的中间的节点数
要缩短访问路径有一种办法,就是多个相互强依赖的应用合并部署在一起,把远程过程调用(RPC)变成JVM内部之间的方法调用。
4、依赖要尽量少
所谓依赖,指的是要完成一次用户请求必须依赖的系统或者服务,这里的依赖指的是强依赖
5、不要有单点
不同场景下的不同架构案例
03二八原则:有针对性地处理好系统的“热点数据”
热点分为热点操作和热点数据
热点操作:大量的刷新页面与大量的添加购物车
热点数据分为:"静态热点数据与动态热点数据"
静态热点
数据是可以提前预测到到,比如某些商品将会大促
静态热点可以通过大数据进行计算,得到Top数据
动态热点
数据是不可以预测的,比如微博某个大V突发事件
如何检测动态热点,
1、构建一个异步的系统,收集各个交易链路上产生的热点key,例如RPC、缓存
2、建立一个热点上报与下发的规范,主要是把已经发现的热带你key透传给下游系统
3、将上游系统收集的热点数据发送到热点服务台,然后下游系统(如交易系统)就会知道哪些商品会被频繁调用,
然后做热点保护
我们通过部署在每台机器上的Agent把日志汇总到聚合和分析集群中,然后把符合一定规则的热点数据,
通过订阅分发系统再推送到相应的系统中。你可以是把热点数据填充到Cache中,或者直接推送到应用服务器的内存中,
还可以对这些数据进行拦截,总之下游系统可以订阅这些数据,然后根据自己的需求决定如何处理这些数据
打造热点发现系统时,我根据以往经验总结了几点注意事项。这个热点服务后台抓取热点数据日志最好采用异步方式,因为“异步”一方面便于保证通用性
,另一方面又不影响业务系统和中间件产品的主流程。
热点服务发现和中间件自身的热点保护模块并存,每个中间件和应用还需要保护自己。热点服务台提供热点数据的收集和订阅服务,便于把各个系统的热点数据透明出来。
热点发现要做到接近实时(3s内完成热点数据的发现),因为只有做到接近实时,动态发现才有意义,才能实时地对下游系统提供保护。
处理热点数据
处理热点数据通常有几种思路:一是优化,二是限制,三是隔离
1、业务隔离
2、系统隔离
3、数据隔离
流量削峰
从0开始学架构
1、框架是什么
软件架构指软件系统的顶层结构
系统与子系统
模块与组件
模块和组件都是系统的组成部分,只是从不同的角度拆分系统而已
框架与架构
框架关注的是“规范”,架构关注的是“结构”。
框架的英文是Framework,架构的英文是Architecture。SpringMVC的英文文档标题就是“WebMVCframework”
3、架构设计目的
架构设计的根本目的是为了解决软件系统复杂度带来的问题
从性能、可扩展性、安全性、成本等多个人方面考虑
4、复杂度来源-性能
单台计算机内部为了高性能带来的复杂度;另一方面是多台计算机集群为了高性能带来的复杂度
单机复杂度
从进程到线程,
多进程多线程虽然让多任务并行处理的性能大大提升,但本质上还是分时系统,并不能做到时间上真正的并行。
集群的复杂度
1、任务分配
横向扩展
2、任务拆解
当各个逻辑任务分解到独立的子系统后,整个系统的性能瓶颈更加容易发现,
而且发现后只需要针对有瓶颈的子系统进行性能优化或者提升,不需要改动整个系统,风险会小很多。
5、复杂度来源-高可用
计算高可用
双机计算需要以下条件
1、需要增加一个任务分配器
2、任务分配器需要增加分配算法
常见的双机算法有主备、主主,主备方案又可以细分为冷备、温备、热备
存储高可用
存储与计算相比,有一个本质上的区别:将数据从一台机器搬到到另一台机器,需要经过线路进行传输。
存储高可用的难点不在于如何备份数据,而在于如何减少或者规避数据不一致对业务造成的影响
高可用状态决策
无论是计算高可用还是存储高可用,其基础都是“状态决策”,
即系统需要能够判断当前的状态是正常还是异常,如果出现了异常就要采取行动来保证高可用。如果状态决策本身都是有错误或者有偏差的,
1.独裁式
独裁式决策指的是存在一个独立的决策主体,我们姑且称它为“决策者”,
负责收集信息然后进行决策;所有冗余的个体,我们姑且称它为“上报者”,都将状态信息发送给决策者
2.协商式
主备决策
主<---->备
这个架构的基本协商规则可以设计成:
2台服务器启动时都是备机。2台服务器建立连接。2台服务器交换状态信息。
某1台服务器做出决策,成为主机;另一台服务器继续保持备机身份。
如果备机在连接中断的情况下认为主机故障, 那么备机需要升级为主机,
但实际上此时主机并没有故障,那么系统就出现了两个主机,这与设计初衷(1主1备)是不符合的
3.民主式
民主式决策指的是多个独立的个体通过投票的方式来进行状态决策。
例如,ZooKeeper集群在选举leader时就是采用这种方式。
民主式决策还有一个固有的缺陷:脑裂。
脑裂式来自医学,指人体左右大脑被切断后,左右大脑无法交换信息,各自做出决定
例如脑裂患者更衣,一只手拉起裤子,一只瘦脱下裤子。
为了解决脑裂问题,民主决策一般都是采用投票节点数量超过系统总节点数一半
6、复杂度来源-可扩展性
预测变化
不能每个设计点都可以考虑到可扩展性
不能完全不考虑可扩展性
所有到预测都存在出错都可能性
应对变化
第一种应对变化都常见方案就是 将"变化"封装在一个"变化层",将不变化的部分封装在一个 独立的稳定层。
无论是变化层依赖稳定层,还是稳定层依赖变化层都是可以的
例如系统会用到的nosql, 可能是redis,后面可能会切到mogo,所以我们就需要提前设计一个
repository层,用来隔离后面的变化
复杂度-系统需要拆分出变化层和稳定层
对于那些是变化层,那些是稳定层,不同的人有不一样的理解
复杂度-需要设计变化层和稳定层之间的接口
提炼出一个“抽象层”和一个“实现层”。抽象层是稳定的,实现层可以根据具体业务需要定制开发,当加入新的功能时
7、复杂度来源-低成本、安全、规模
低成本
NoSQL(Memcache、Redis等)的出现是为了解决关系型数据库无法应对高并发访问带来的访问压力
全文搜索引擎(Sphinx、Elasticsearch、Solr)的出现是为了解决关系型数据库like搜索的低效的问题
Hadoop的出现是为了解决传统文件系统无法应对海量数据存储和计算的问题。
新浪微博将传统的Redis/MC+MySQL方式,扩展为Redis/MC+SSDCache+MySQL方式,
SSDCache作为L2缓存使用,既解决了MC/Redis成本过高,容量小的问题,也解决了穿透DB带来的数据库访问压力
Linkedin为了处理每天5千亿的事件,开发了高效的Kafka消息系统
安全
1、功能安全
xss、csrf、sql注入
2、架构安全
防火墙,ddos
互联网系统的架构安全目前并没有太好的设计手段来实现,更多地是依靠运营商或者云服务商强大的带宽和流量清洗的能力,较少自己来设计和实现
规模
1.功能越来越多,导致系统复杂度指数级上升
各个功能相互耦合
2.数据越来越多,系统复杂度发生质变
例如mysql数据量变多,就要考虑分库分表
08架构设计三原则
业务千变万化,技术层出不穷,设计理念也是百花齐放,看起来似乎很难有一套通用的规范来适用所有的架构设计场景。
但是在研究了架构设计的发展历史、多个公司的架构发展过程(QQ、淘宝、Facebook等)、众多的互联网公司架构设计后,
我发现有几个共性的原则隐含其中,这就是:合适原则、简单原则、演化原则,架构设计时遵循这几个原则,有助于你做出最好的选择。
合适原则(合适优于业界领先)
不能硬搬别人的架构,想达到业界领先的水平。因为你没有别人公司的团队配置,和积累,以及业务场景,所以不能硬套方案
简单原则(简单优于复杂)
结构复杂的系统几乎毫无例外具备两个特点:组成复杂系统的组件数量更多;同时这些组件之间的关系也更加复杂。
某个组件改动,会影响关联的所有组件
定位一个复杂系统中的问题总是比简单系统更加困难
演化原则 (演化优于一步到位)
架构师在进行架构设计时需要牢记这个原则,时刻提醒自己不要贪大求全,或者盲目照搬大公司的做法。
应该认真分析当前业务的特点,明确业务面临的主要问题,设计合理的架构,快速落地以满足业务需要,然后在运行过程中不断完善架构,不断随着业务演化架构
即使是大公司的团队,在设计一个新系统的架构时,也需要遵循演化的原则,而不应该认为团队人员多、资源多,
不管什么系统上来就要一步到位,因为业务的发展和变化是很快的,不管多牛的团队,也不可能完美预测所有的业务发展和变化路径。
10、架构设计流程
架构设计第1步:识别复杂度
将主要的复杂度问题列出来,然后根据业务、技术、团队等综合情况进行排序,优先解决当前面临的最主要的复杂度问题。
识别复杂度(消息队列)
1、这个消息队列是否需要高性能
2、这个消息队列是否需要高可用性
3、这个消息队列是否需要高可扩展性
架构设计第2步:设计备选方案
架构师的工作并不神秘,成熟的架构师需要对已经存在的技术非常熟悉,对已经经过验证的架构模式烂熟于心,
然后根据自己对业务的理解,挑选合适的架构模式进行组合,再对组合后的方案进行修改和调整
技术组合
NoSQL:KeyValue的存储和数据库的索引其实是类似的,
Memcache只是把数据库的索引独立出来做成了一个缓存系统。
Hadoop大文件存储方案,基础其实是集群方案+数据复制方案。
Docker虚拟化,基础是LXC(LinuxContainers)。
LevelDB的文件存储结构是SkipList。
场景误区
1、设计最优秀的答案
2、只做一个方案
备选方案的数量以3~5个为最佳,
备选方案的差异要比较明显
备选方案的技术不要只局限于已经熟悉的技术
3、备选方案过于详细
设计备选方案实战(消息队列)
1、采用开源的Kafka
2、集群+MySQL存储
3、集群+自研存储方案
架构设计第3步:评估和选择备选方案
列出我们需要关注的质量属性点,然后分别从这些质量属性的维度去评估每个方案,再综合挑选适合当时情况的最优方案
常见的方案质量属性点有:性能、可用性、硬件成本、项目投入、复杂度、安全性、可扩展性等。
在评估这些质量属性时,需要遵循架构设计原则1“合适原则”和原则2“简单原则”,避免贪大求全,
基本上某个质量属性能够满足一定时期内业务发展就可以了。
架构设计第4步:详细方案设计
详细方案设计就是将方案涉及的关键技术细节给确定下来
详细方案实战(消息队列)
1、数据库表如何设计
数据库设计两类表,一类是日志表,用于消息写入时快速存储到MySQL中;另一类是消息表,每个消息队列一张表。
业务系统发布消息时,首先写入到日志表,日志表写入成功就代表消息写入成功;
后台线程再从日志表中读取消息写入记录,将消息内容写入到消息表中。
业务系统读取消息时,从消息表中读取。
日志表表名为MQ_LOG,包含的字段:日志ID、发布者信息、发布时间、队列名称、消息内容。
2、数据如何复制
直接采用MySQL主从复制即可,只复制消息存储表,不复制日志表
3、业务服务器如何写入消息
消息队列系统设计两个角色:生产者和消费者,每个角色都有唯一的名称。
消息队列系统提供SDK供各业务系统调用,SDK从配置中读取所有消息队列系统的服务器信息,
SDK采取轮询算法发起消息写入请求给主服务器。如果某个主服务器无响应或者返回错误,SDK将发起请求发送到下一台服务器。
14、高性能数据库集群-读写分离
读写分离的基本实现
- 数据库服务器搭建主从集群,一主一从、一主多从都可以。
- 数据库主机负责读写操作,从机只负责读操作。数据库主机通过复制将数据同步到从机,每台数据库服务器都存储了所有的业务数据。
- 业务服务器将写操作发给数据库主机,将读操作发给数据库从机。
需要注意的是,这里用的是“主从集群”,而不是“主备集群”。“从机”的“从”可以理解为“仆从”,仆从是要帮主人干活的, “从机”是需要提供读数据的功能的;而“备机”一般被认为仅仅提供备份功能,不提供访问功能。 所以使用“主从”还是“主备”,是要看场景的,这两个词并不是完全等同的。
复制延迟
主从复制会有延迟,如果写入到主库的数据 要马上查询到,就需要强制走主库查询分配机制
中间件与代码封装
15、高性能数据库集群-分库分表
业务分库
1、join操作问题
2、事物问题
3、成本问题
分表
垂直分表和水平分表
16、高性能NOSQL
常见的NoSQL方案分为4类。
KV存储:解决关系数据库无法存储数据结构的问题,以Redis为代表。
文档数据库:解决关系数据库强schema约束的问题,以MongoDB为代表。
列式数据库:解决关系数据库大数据场景下的I/O问题,以HBase为代表。
全文搜索引擎:解决关系数据库的全文搜索性能问题,以Elasticsearch为代表。
mogodb
为了解决关系数据库schema带来的问题,文档数据库应运而生。文档数据库最大的特点就是noschema,可以存储和读取任意的数据。
所存即所见
优点:
1、新增字段简单
2、历史数据不会出错
3、可以很容易存储复杂数据
MYSQL实战45讲
1、基础架构-一条SQL查询语句是如何执行的
MYSQL的逻辑架构图
Server层
连接层-》查询缓存-》分析器-》优化器-》执行器
mysql -h$ip -P$port -u$user -p
优化器
优化器是在表里面有多个索引的时候,决定使用哪个索引;
或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序
存储引擎层
Innodb、MyIsam、Memory
2、基础架构-一条SQL更新语句是如何执行的
重要的日志模块:redolog
MySQL里经常说到的WAL技术,WAL的全称是WriteAheadLogging,它的关键点就是先写日志,再写磁盘,也就是先写粉板,等不忙的时候再写账本。
最开始MySQL里并没有InnoDB引擎。MySQL自带的引擎是MyISAM,但是MyISAM没有crashsafe的能力,
binlog日志只能用于归档。而InnoDB是另一个公司以插件形式引入MySQL的,既然只依靠binlog是没有crashsafe能力的,
所以InnoDB使用另外一套日志系统——也就是redolog来实现crashsafe能力
redolog与binlog区别
redolog是InnoDB引擎特有的;binlog是MySQL的Server层实现的,所有引擎都可以使用
3、事务隔离:为什么你改了我还看不见
ACID(Atomicity、Consistency、Isolation、Durability,即原子性、一致性、隔离性、持久性)
在谈隔离级别之前,你首先要知道,你隔离得越严实,效率就会越低
多版本并发控制(MVCC)+,回滚日志实现事物
4、深入浅出索引(上)
索引的常见模型
哈希表、有序数组、搜索树
哈希表适用于等值查询场景,不适合区间查询,因为需要遍历所有
有序数组适用于静态存储,因为设计到插入和删除就需要挪动所有记录。
搜索二叉树搜索效率最高,但是需要考虑到存储,如果二叉树到度越高,就需要越多到磁盘寻址时间,
所有一般用B+树
InnoDB的索引模型
,索引类型分为主键索引和非主键索引。主键索引的叶子节点存的是整行数据。
在InnoDB里,主键索引也被称为聚簇索引(clusteredindex)。
非主键索引的叶子节点内容是主键的值。在InnoDB里,非主键索引也被称为二级索引(secondaryindex)。
索引维护
显然,主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小
5、深入浅出索引(下)
回到主键索引树搜索的过程,我们称为回表
覆盖索引
select ID from T where k between 3 and 5,这时只需要查ID的值,而ID的值已经在k索引树上了,
因此可以直接提供查询结果,不需要回表。也就是说,在这个查询里面,索引k已经“覆盖了”我们的查询需求,
我们称为覆盖索引,由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段
最左前缀原则
B+树这种索引结构,可以利用索引的“最左前缀”,来定位记录
多个字段建立的索引,组合索引的最左侧字段必须出现在查询组句中,不然会导致索引失效
索引下推
以市民表的联合索引(name,age)为例,
检索出表中“名字第一个字是张,而且年龄是10岁的所有男孩”。
那么,SQL语句是这么写的:select * from t user where name like'张%' and age=10 and ismale=1;
你已经知道了前缀索引规则,所以这个语句在搜索索引树的时候,只能用“张”,找到第一个满足条件的记录ID为3的数据。
在mysql5.6之前 需要根据ID=3 去回表查询主键索引的数据行,再去比较字段值
在mysql5.6之后 引入的索引下推优化(index condition pushdown) 可以在索引遍历的过程中,对索引的中
包含的字段先做判断,直接过滤到不满足条件的记录,减少回表数
6、全局锁和表锁:给表加个字段怎么有这么多阻碍?
根据加锁的范围,MySQL里面的锁大致可以分成全局锁、表级锁和行锁三类
全局锁
全局锁是对整个数据库实例加锁,mysql提供了一个全局读锁读方法,flush tables with read lock(FTWRL)
全局锁的典型使用场景是,做全库逻辑备份
官方自带的逻辑备份工具是mysqldump。当mysqldump使用参数–singletransaction的时候,
导数据之前就会启动一个事务,来确保拿到一致性视图。而由于MVCC的支持,这个过程中数据是可以正常更新的。
你也许会问,既然要全库只读,为什么不使用set global readonly=true的方式呢?
一是,在有些系统中,readonly的值会被用来做其他逻辑,比如用来判断一个库是主库还是备库。因此,修改global变量的方式影响面更大,我不建议你使用。
二是,在异常处理机制上有差异。如果执行FTWRL命令之后由于客户端发生异常断开,
那么MySQL会自动释放这个全局锁,整个库回到可以正常更新的状态。而将整个库设置为readonly之后,
如果客户端发生异常,则数据库就会一直保持readonly状态,这样会导致整个库长时间处于不可写状态,风险较高。
表级锁
mysql表锁有两种 一种是表锁,一种是元数据锁 MDL(meta data lock )
表锁一般是在数据库引擎不支持行锁的时候才会被用到的,例如myisam不支持事物的引擎
lock tables
表锁的语法是lock tables…read/write。与FTWRL类似,可以用unlock tables主动释放锁
对于InnoDB这种支持行锁的引擎,一般不使用lock tables命令来控制并发,毕竟锁住整个表的影响面还是太大
MDL
MDL不需要显式使用,在访问一个表的时候会被自动加上,作用是保证读写的正确性,例如你正在执行遍历查询的时候,
这时候另外一个线程对表数据结构做改变,你删除了一条 肯定不行的。
在mysql5.5版本汇总引入了mdl.
当对一个表增删改查当时候加mdl读锁,
当对表做结构变更时候加dml写锁
读锁直接不互斥,读写锁或者写锁之间是互斥的,如果两个线程同时给一个表加字段,需要等另外一个线程执行万
Mysql不锁表增加字段和索引方法
1、
ALTER TABLE `member` ADD `user_from` smallint(1) NOT NULL, ALGORITHM=INPLACE, LOCK=NONE
5.6 以后增加了ONLINE DDL,实现不锁表增加字段和索引非常简单
ALGORITHM表示算法:
default默认(根据具体操作类型自动选择),
inplace(不影响DML),
copy创建临时表(锁表),
INSTANT只修改元数据(8.0新增,在修改名字等极少数情况可用)
LOCK表示是否锁表:
default默认,none,shared共享锁,exclusive
2、 使用 pt-online-schema-change 工具
给小表加字段或者修改字段,或者加索引,导致服务不可用
例如有
session A select * from t 读锁
session b select * from t 读锁
session c alter t add cloumn 写锁 blocked
session D select * from t 读锁 blocked (读写互斥)
如果t表查询比较频繁,同时客户端有重试功能,当查询请求被block时候,会重新场景一个新的session,会导致库的链接线程被打满
如何安全给小表加字段?
在alter table语句里面设定等待时间,如果在这个指定的等待时间里面能够拿到MDL写锁最好,
拿不到也不要阻塞后面的业务语句,先放弃。之后开发人员或者DBA再通过重试命令重复这个过程。
ALTER TABLE tbl_name WAIT N add column
7、行锁功过:怎么减少行锁对性能的影响?
MySQL的行锁是在引擎层由各个引擎自己实现的。但并不是所有的引擎都支持行锁,比如MyISAM引擎就不支持行锁。
不支持行锁意味着并发控制只能使用表锁,对于这种引擎的表,同一张表上任何时刻只能有一个更新在执行,这就会影响到业务并发度。
InnoDB是支持行锁的,这也是MyISAM被InnoDB替代的重要原因之一
两阶段锁
在InnoDB事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。
这个就是两阶段锁协议,如果你的事务中需要锁多个行,要把最可能造成锁冲突、最可能影响并发度的锁尽量往后放
死锁和死锁检测
当并发系统中不同线程出现循环资源依赖,涉及的线程都在等待别的线程释放资源时,就会导致这几个线程都进入无限等待的状态,称为死锁
当出现死锁以后,有两种策略
1、直接等待,直到超时,超时时间 数innodb_lock_wait_timeout(默认50S)
2、发起死锁检测,发现死锁后,主动回滚死锁链条中的某一个事务,让其他事务得以继续执行。
将参数innodb_deadlock_detect设置为on,表示开启这个逻辑(推荐这种方式)
但是死锁检测需要耗费大量的CPU资源
如何避免死锁
控制同行并发数量
1)以固定的顺序访问表和行。比如对第2节两个job批量更新的情形,简单方法是对id列表先排序,后执行,这样就避免了交叉等待锁的情形;
又比如对于3.1节的情形,将两个事务的sql顺序调整为一致,也能避免死锁。
2)大事务拆小。大事务更倾向于死锁,如果业务允许,将大事务拆小。
3)在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁概率。
4)降低隔离级别。如果业务允许,将隔离级别调低也是较好的选择,比如将隔离级别从RR调整为RC,可以避免掉很多因为gap锁造成的死锁。
5)为表添加合理的索引。可以看到如果不走索引将会为表的每一行记录添加上锁,死锁的概率大大增大。
08、事务到底是隔离的还是不隔离的
快照读
在可重复读隔离级别下,事务在启动的时候就“拍了个快照”。注意,这个快照是基于整库的
,InnoDB利用了“所有数据都有多个版本”的这个特性,实现了“秒级创建快照”的能力
更新数据都是先读后写的,而这个读,只能读当前的值,称为“当前读”(currentread)
09、普通索引和唯一索引,应该怎么选择?
从性能的角度考虑,你选择唯一索引还是普通索引呢?选择的依据是什么呢
。其实,这两类索引在查询能力上是没差别的,主要考虑的是对更新性能的影响。所以,我建议你尽量选择普通索引
查询过程
执行查询的语句是select id from T where k=5
先是通过B+树通过树根开始,按层搜到叶子节点,然后找到对应的数据页,然后在数据页里面通过二分查找法定位到记录
1、对于普通索引来说,查找到满足条件的第一个记录(5,500)后,需要查找下一个记录,直到碰到第一个不满足k=5条件的记录。
2、对于唯一索引来说,由于索引定义了唯一性,查找到第一个满足条件的记录后,就会停止继续检索
那么,这个不同带来的性能差距会有多少呢?答案是,微乎其微
因为引擎是按页读写的,所以说,当找到k=5的记录的时候,它所在的数据页就都在内存里了。
那么,对于普通索引来说,要多做的那一次“查找和判断下一条记录”的操作,就只需要一次指针寻找和一次计算
10、MySQL为什么有时候会选错索引
优化器的逻辑
选择索引是优化器的工作,扫描行数、临时表、收否排序等综合因素判断
MySQL选错索引,这件事儿还得归咎到没能准确地判断出扫描行数,(例如我们大量删除数据,有增加数据)
使用analyze table t 可以用来重新统计索引信息
使用普通索引需要把回表的代价算进去
索引选择异常和处理
一种方法是,像我们第一个例子一样,采用forceindex强行选择一个索引
第三种方法是,在有些场景下,我们可以新建一个更合适的索引,来提供给优化器做选择,或删掉误用的索引。
11、怎么给字符串字段加索引
使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本
当要给字符串创建前缀索引时,有什么方法能够确定我应该使用多长的前缀呢
select count(distinct left(email,4))as L4,
count(distinct left(email,5))as L5,
count(distinct left(email,6))as L6,
count(distinct left(email,7))asL7,
from SUser
当然,使用前缀索引很可能会损失区分度,所以你需要预先设定一个可以接受的损失比例,比如5%。
然后,在返回的L4~L7中,找出不小于95%的值,假设这里L6、L7都满足,你就可以选择前缀长度为6。
前缀索引对覆盖索引的影响
所以,如果使用index1(即email整个字符串的索引结构)的话,可以利用覆盖索引,从index1查到结果后直接就返回了,不需要回到ID索引再去查一次。
而如果使用index2(即email(6)索引结构)的话,就不得不回到ID索引再去判断email字段的值。
前缀索引的区分度不够好的情况时,我们要怎么办呢?
1、第一种方式是使用倒序存储
例如